最近arxiv开始陆陆续续上ICML格式的文章了,公式浓度明显上升。
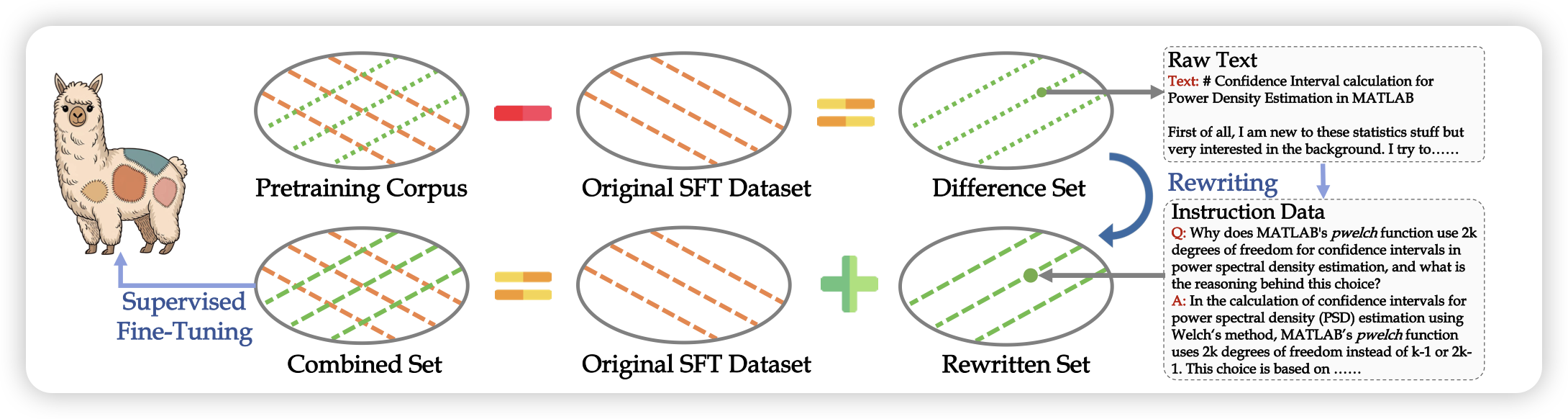
Learnings from Scaling Visual Tokenizers for Reconstruction and Generation
meta最近好像一直在和tokenizer死磕,这篇工作作者尝试对于ViT image tokenizer的scaling问题。基于对下游的perception和generation的效果进行观察
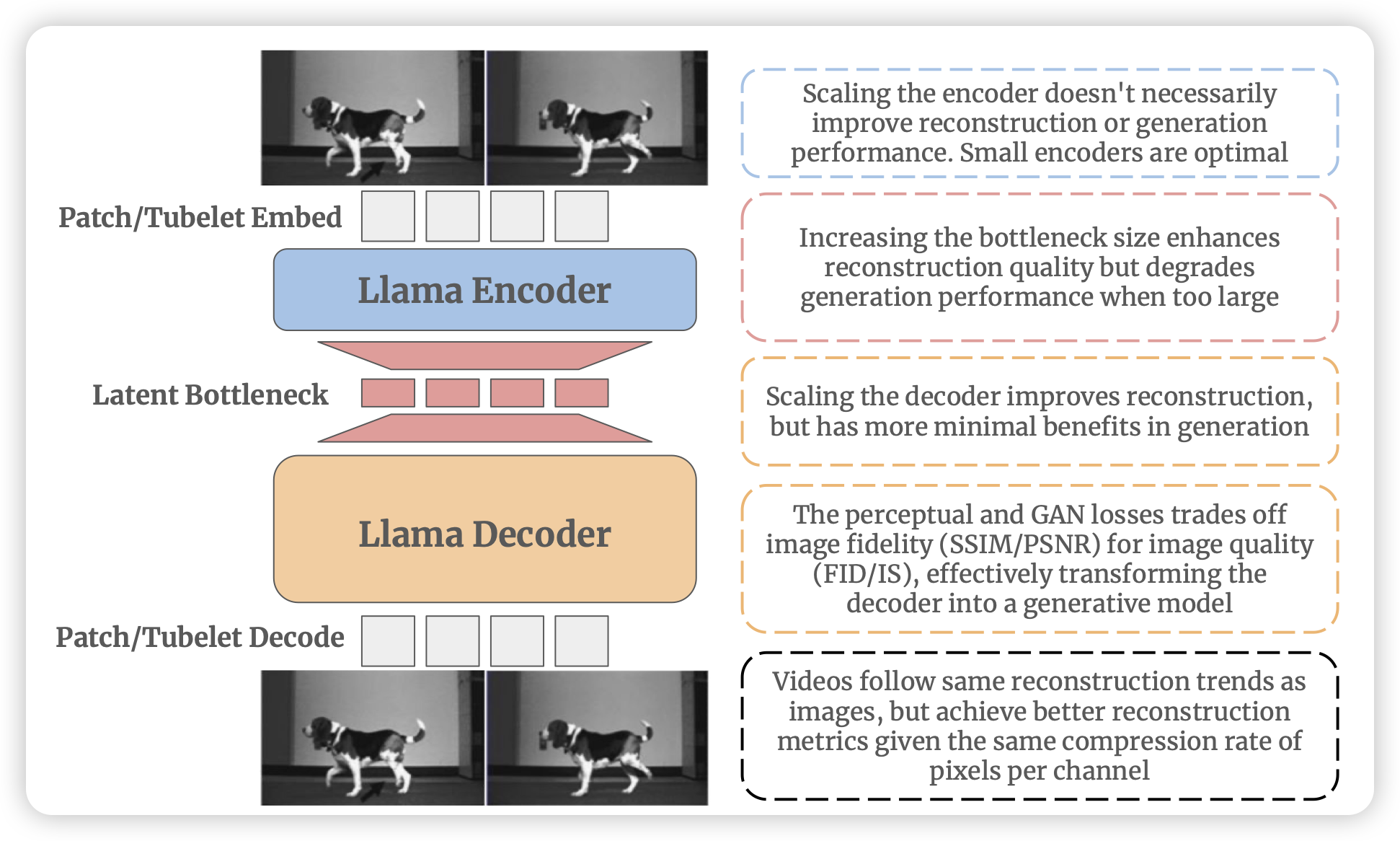
Aligning Instruction Tuning with Pre-training
一篇挺有趣的工作,作者认为:既然SFT的目的是激发模型运用预训练的知识,那么其实就要求SFT数据在知识分布上需要和预训练尽可能对齐。现在是否对齐了呢?作者去找到一种方法,识别pretrain数据和sft数据的domain gap,由此对sft数据进行补充。