有种微妙的感觉,似乎最近大家变得越来越接近AGI了…难道是因为NeruIPS论文开始往外挂了?
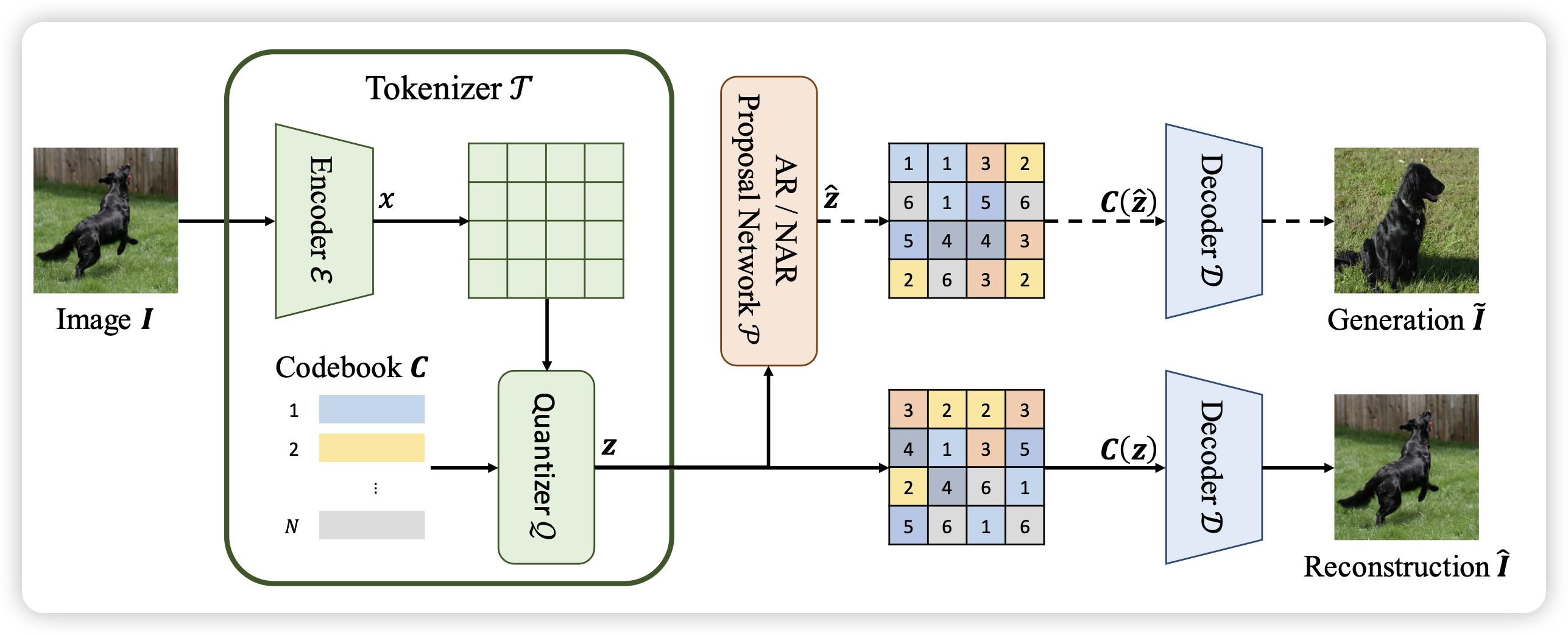
Image Understanding Makes for A Good Tokenizer for Image Generation
字节的工作,作者发现VAE中的encoder,做出来的词表作为image generation的输入,可以促进图像生成的水平
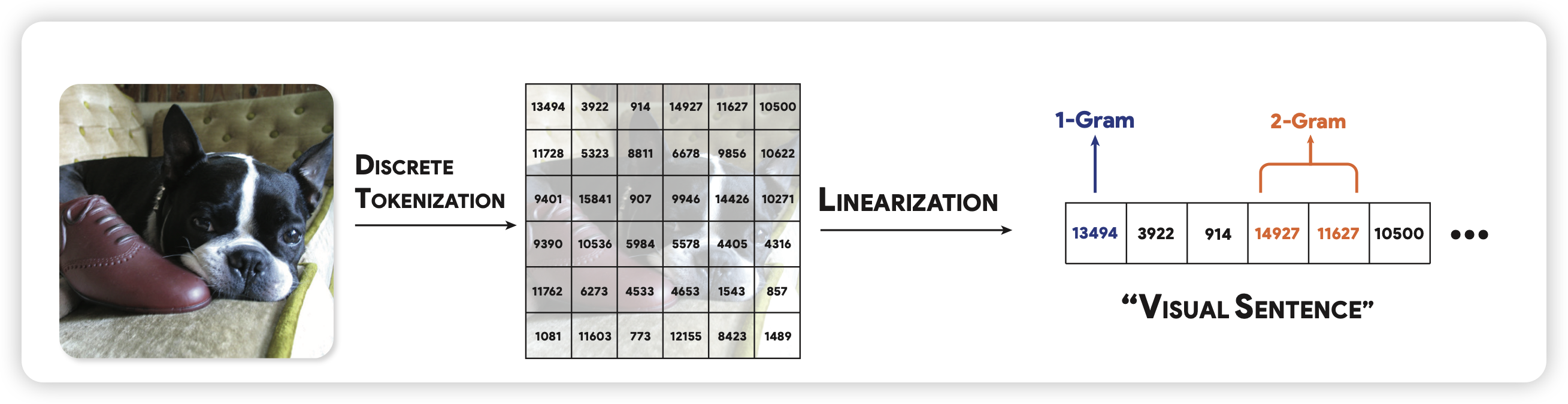
Analyzing The Language of Visual Tokens
很有趣的工作!大家都知道目前VLM基本都是把图片编码成多个token丢给LLM,那么。这些token本身会不会形成语言呢?作者做了很多分析,得出了好玩的结论
ReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
前几天pika搞了个 camera-control,今天学术复刻版就出来了。可以输入一个原视频,然后生成一个你想要的分镜的版本

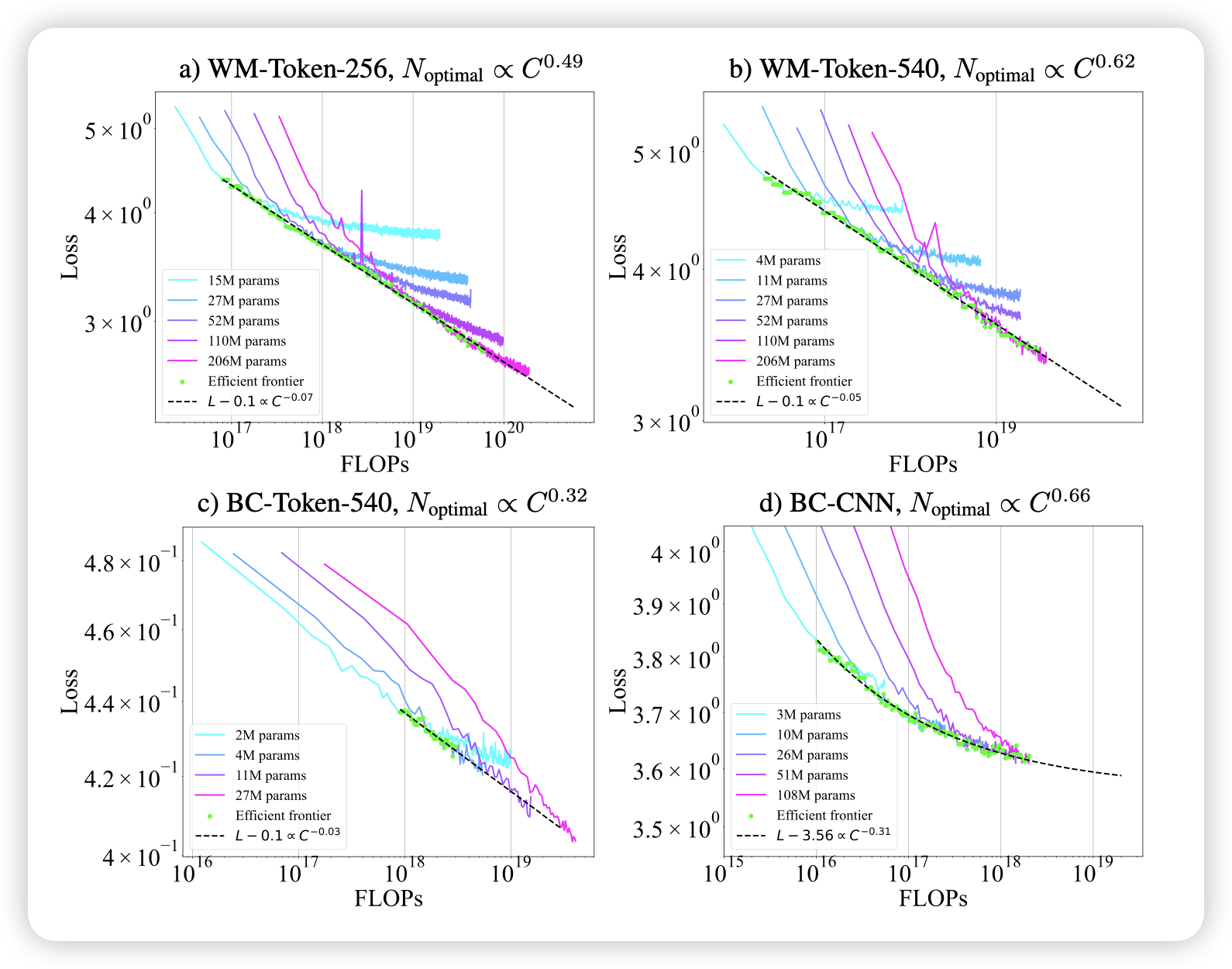
Scaling Laws for Pre-training Agents and World Models
名字够狂,再一看:microsoft research。作者讨论的是,在今天很火的agent-sft和world-modelling这两个领域,是否存在数据、模型参数的scaling law,进而套用chinchilla那套compute optimal理论呢?作者发现还真是
有公式做题就是快……
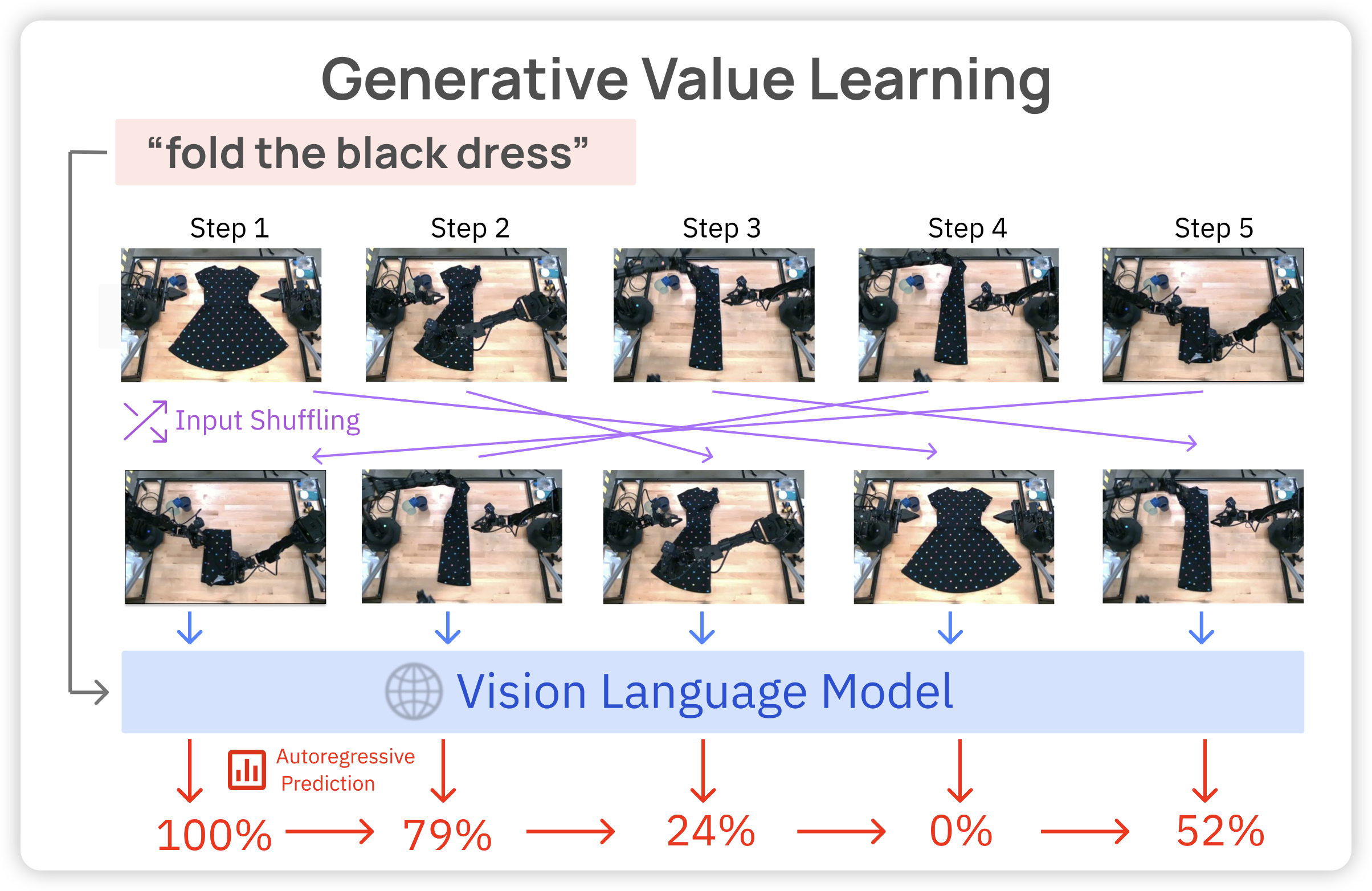
Vision Language Models are In-Context Value Learners
deepmind的工作,前几天字节有个工作发现autoregressive image generation中,把patch顺序做shuffle有正面影响(Randomized Autoregressive Visual Generation)。今天deepmind搞了个新东西?如果把视频中的帧打乱,让一个value model通过Autoregressive的方式预测每一帧原来的视频时间呢?作者认为这是一个in-context的过程,随着给的图片越来越多,模型在context中学习到了任务
很有意思!因为视频帧恰好具有独特性,基本上不会找到相同的两个帧……所以,这是小学的选词造句对吧,但是只能看一遍
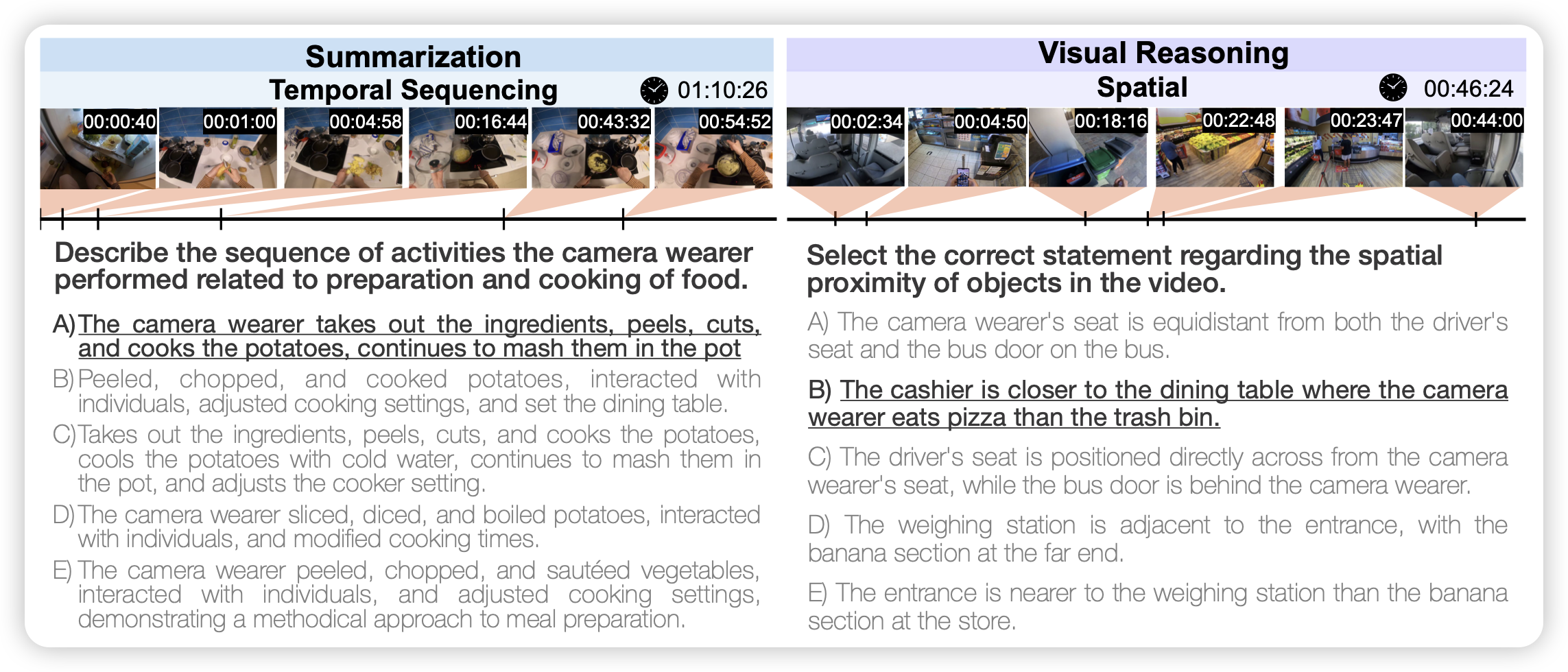
HourVideo: 1-Hour Video-Language Understanding
李飞飞的工作,作者设计了一万到题,都是20min-120min的视频,涉及到视频理解的放放面面。
感觉最近很多人都搞了类似的东西,这个时候可能就是比谁名气大了……
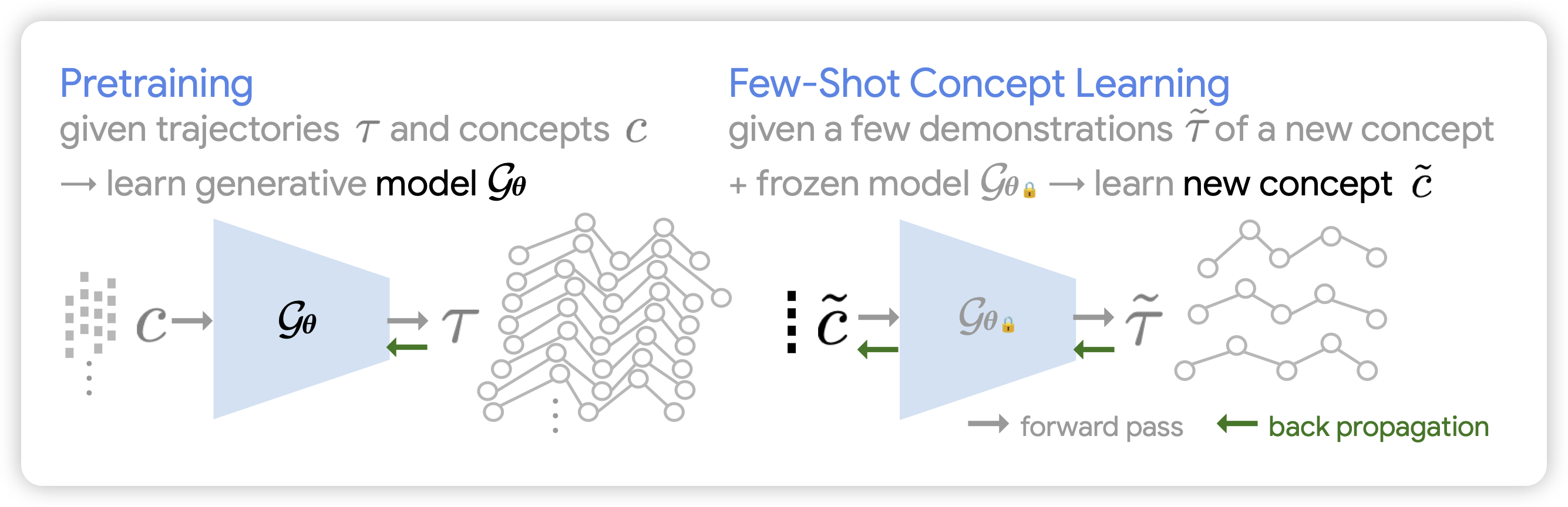
Few-Shot Task Learning through Inverse Generative Modeling
一篇挺怪的动作,作者认为,已有的agent policy model可以给出concept去生成动作。如果我已经有了policy,在没见过的concept的demonstration上反过来求梯度,能不能生成对应的concept呢?
有点怪,主要是,这件事依赖于有unseen concept的demonstration,什么时候会这样呢?