今天的工作竟然全是和entropy关闭相关的
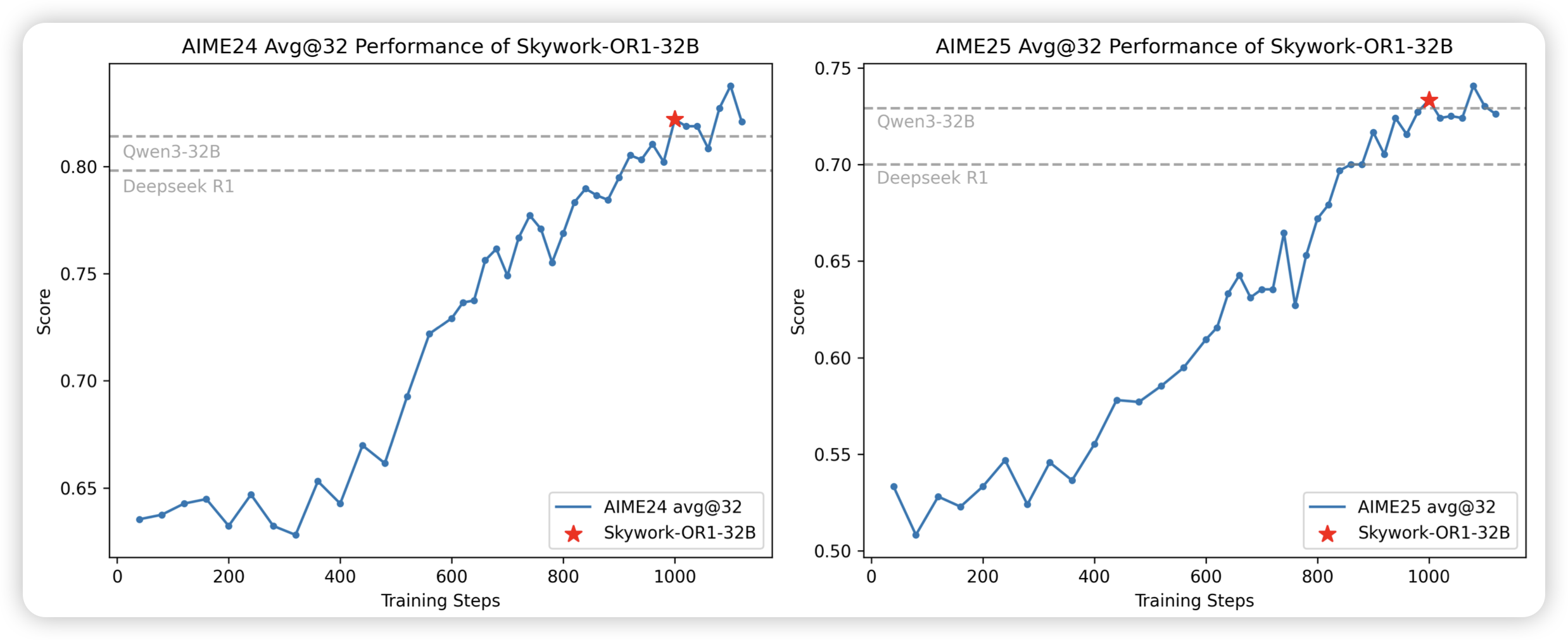
Skywork Open Reasoner 1 Technical Report
skywork的o1工作,时隔多年,终于做出来了。作者也讲到了在训练中,维持entropy稳定的重要性
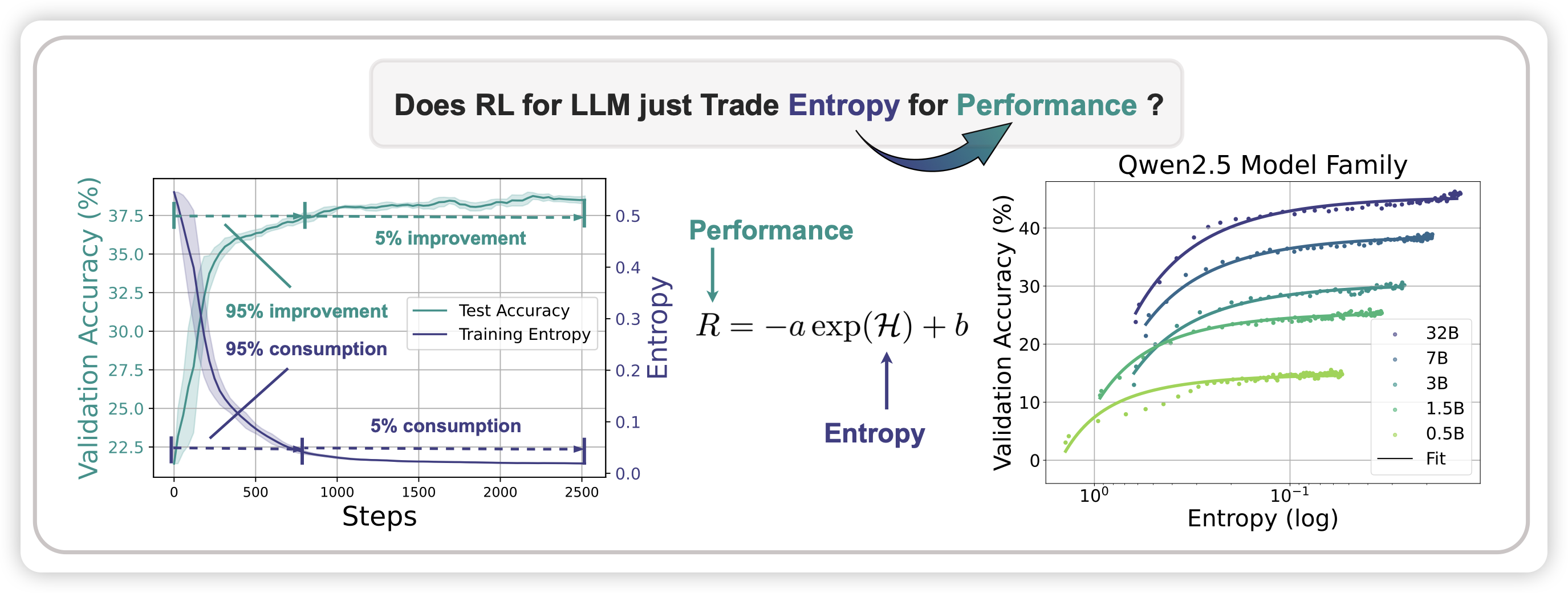
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
ganqu师兄的工作。作者探讨了在rl过程中entropy关闭的问题,也就是说。rl后的模型,基本上开不开sample都差不多,因为top1 token占据了绝对优势。作者发现,这主要来源于训练时高概率的动作有更大的概率效果不错,进而让模型非常确信自己高概率的动作。通过一些算法上的改进,可以缓解这个问题。
这个和底下那个工作讲的是一个事情呀
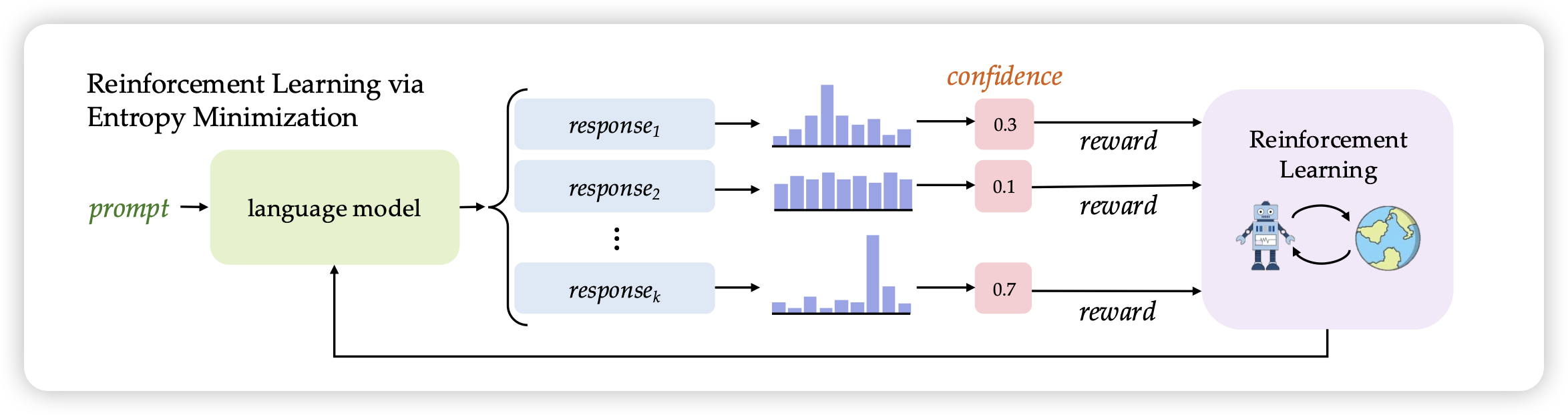
Maximizing Confidence Alone Improves Reasoning
这篇工作中,作者尝试把rl场景的reward换成answer ppl。是的,就是不管答案对不对,只要ppl低就给分高。神奇的是,这个训练甚至有收益。作者把方法名叫做rent,感觉还蛮有深意的
最近还有一篇工作发现给假reward也有收益