回来上班了,接下来5天每天推两天的工作,把arxiv里救回来一周的工作。
Competitive Programming with Large Reasoning Models
OpenAI的工作,白名单机构,看见直接推。是o1和o3-preview在ioi和codeforce的测试报告。
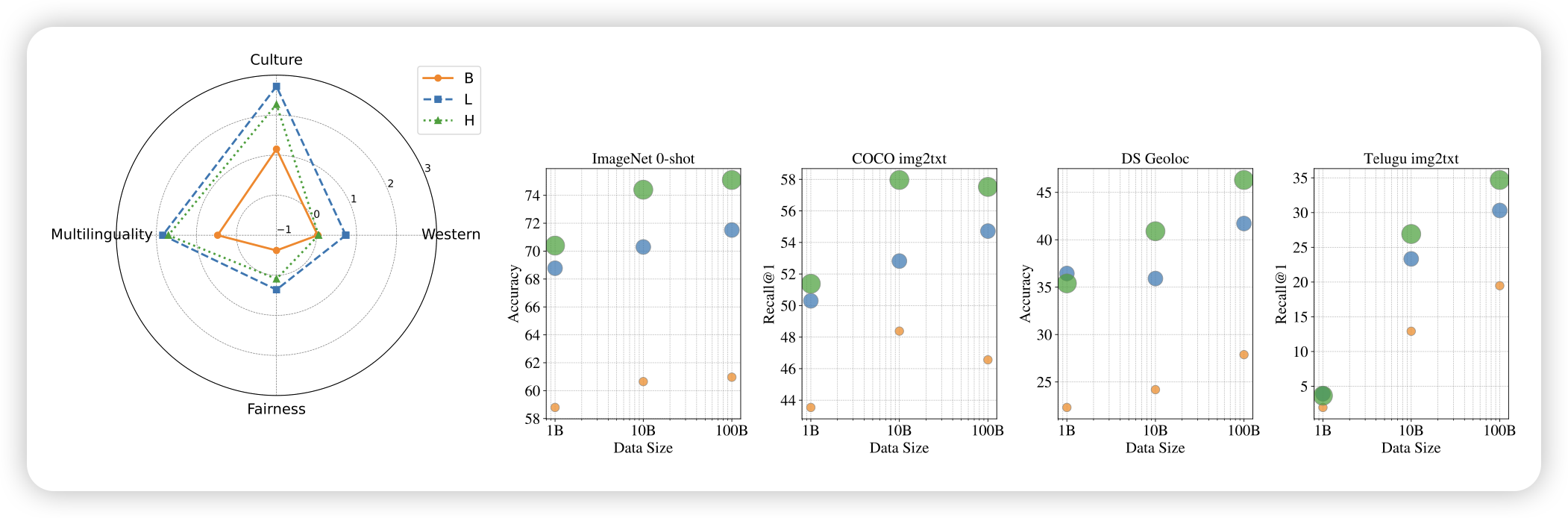
Scaling Pre-training to One Hundred Billion Data for Vision Language Models
Google的工作,作者尝试了把VLM训练数据scaling到100B条。大致结论是:
- 常见benchmark,比如coco,基本10B数据就收敛了
- 罕见benchmark,可以一直训一直涨
- 使用data filter,比如clip,即使做的很细,还是会掉分?……所以,大家真的需要filter吗
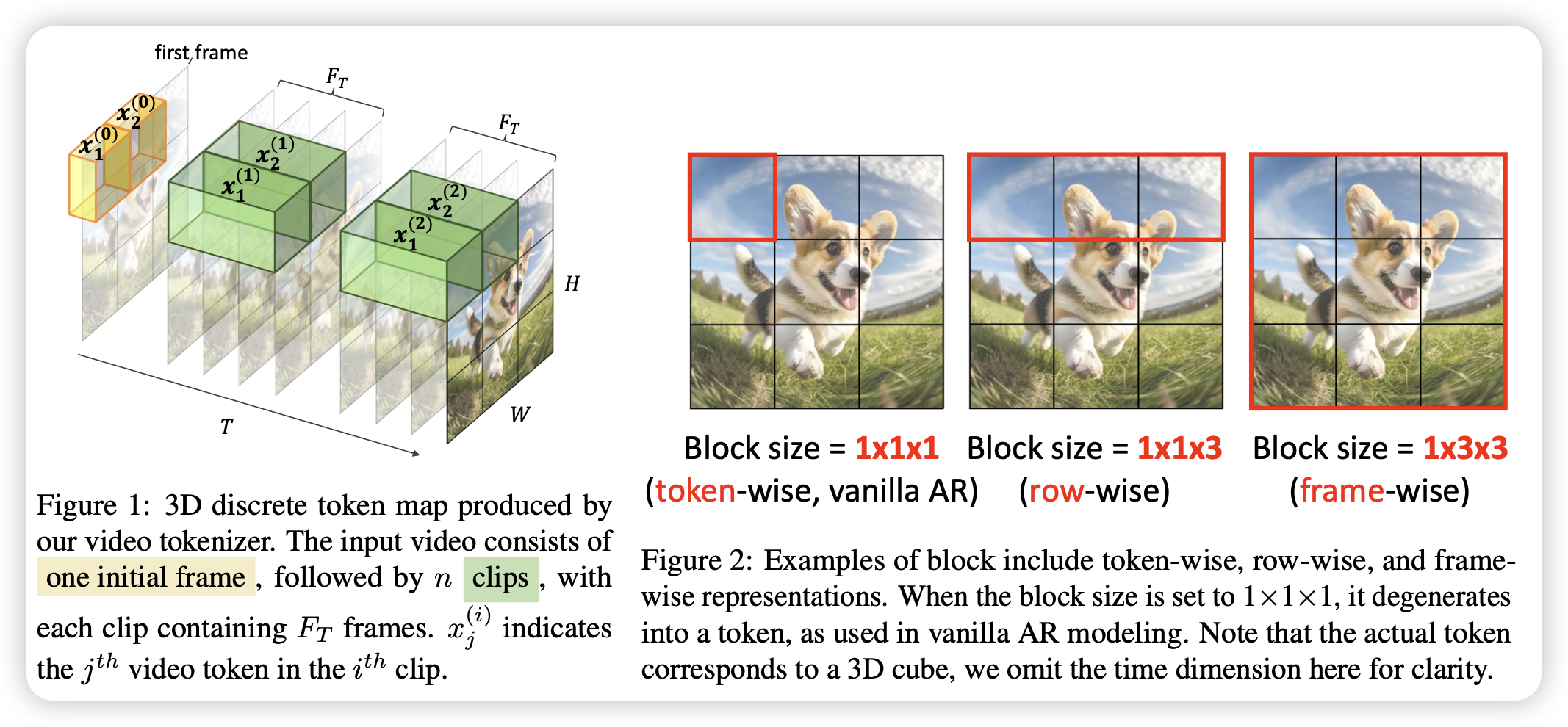
Next Block Prediction: Video Generation via Semi-Autoregressive Modeling
Furu组的论文,他们取名字总是有一手的。作者认为,目前的Autoregressive video generation大多数都是按照时间从前到后,单张图image patch按扫描顺序上到下、左到右,能不能换成一个block一个block生成,而不是一个patch呢?作者尝试了next block generation,一个block甚至可以是跨时间的,比如说一个区域一段时间内的子内容,发现效果很好。
我觉得这背后有一个观点在于:时间从前到后,单张图image patch按扫描顺序上到下、左到右,这样的逻辑是否真的是casual的?因为Autoregressive需要被建模的对象具有好的casual性质,这点在video模态里其实并不显然。可能,我们甚至需要想到一些办法对casual做建模,比如vqvae那样子?