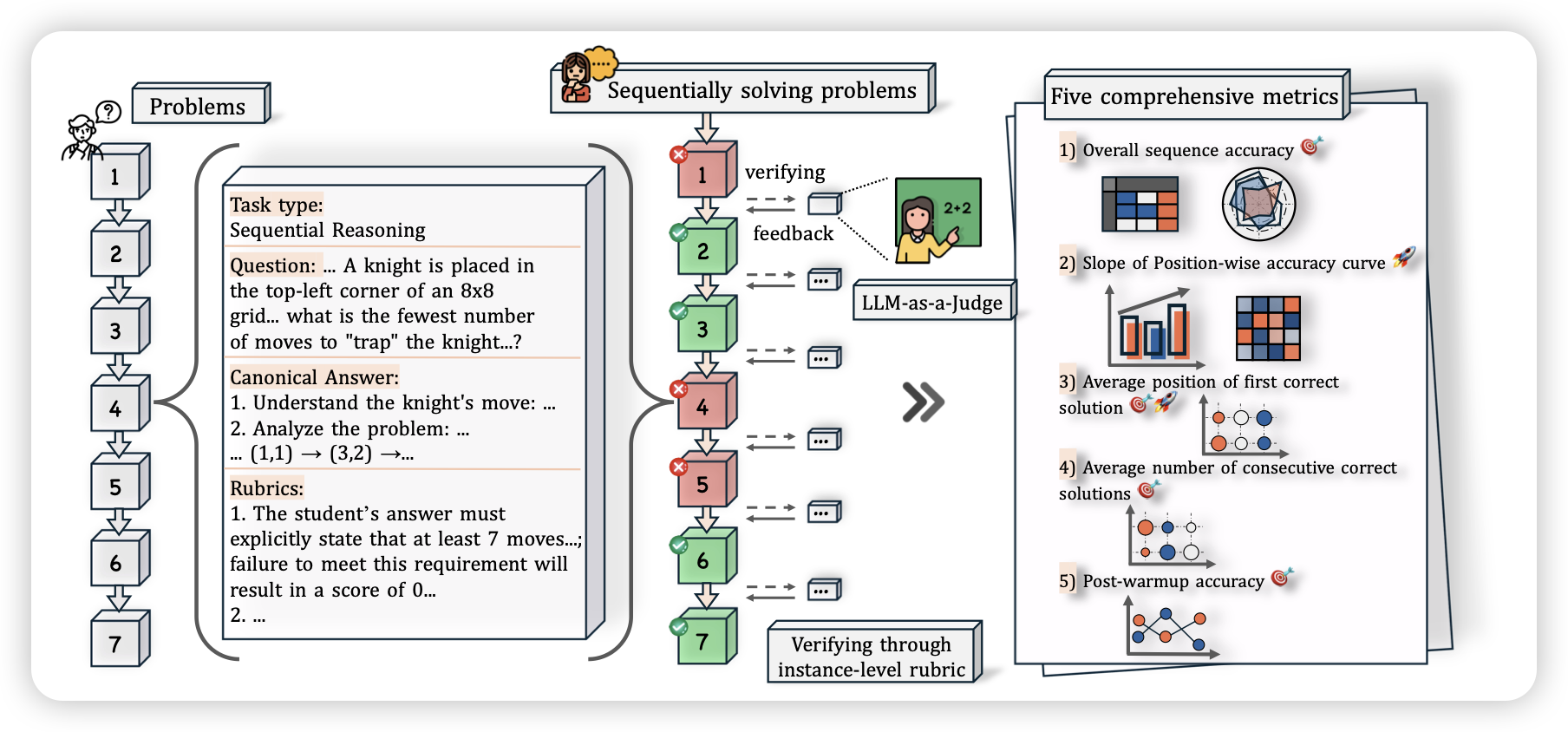
EvaLearn: Quantifying the Learning Capability and Efficiency of LLMs via Sequential Problem Solving
seed的工作,作者定义了一个场景叫“sequential problem solving”,就是把几道类似的题放到一个batch里,用多轮的形式一次全做了。看这个setting上模型能不能在完成任务的过程中learn and adapt。
话说最近这种in-context learning的工作越来越多了,在gui领域大家叫tutorial。在text-only上可能就是这种类似sequential problem solving的setting
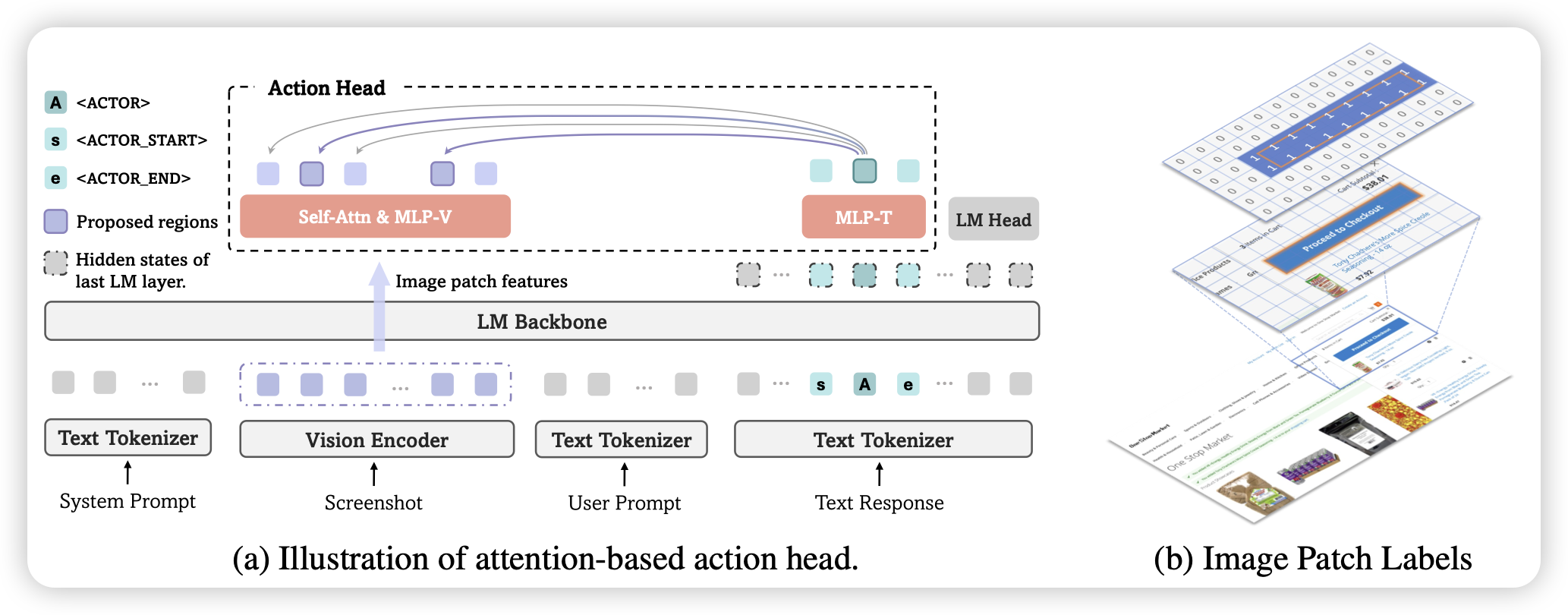
GUI-Actor: Coordinate-Free Visual Grounding for GUI Agents
和下面那个类似,也是一个gui grounding的工作。这篇的思路有点像apple之前的ferret系列,作者不是用数字的形式预测坐标文本,而是用一个特殊token代表坐标(给出类似于热力图的预测),然后解码到坐标空间。通过这种方案,作者进一步做了verifier来选择不同的变体
我其实纠结过很长时间box的表示形式应该用文本还是特殊token,现在感觉可能各有利弊
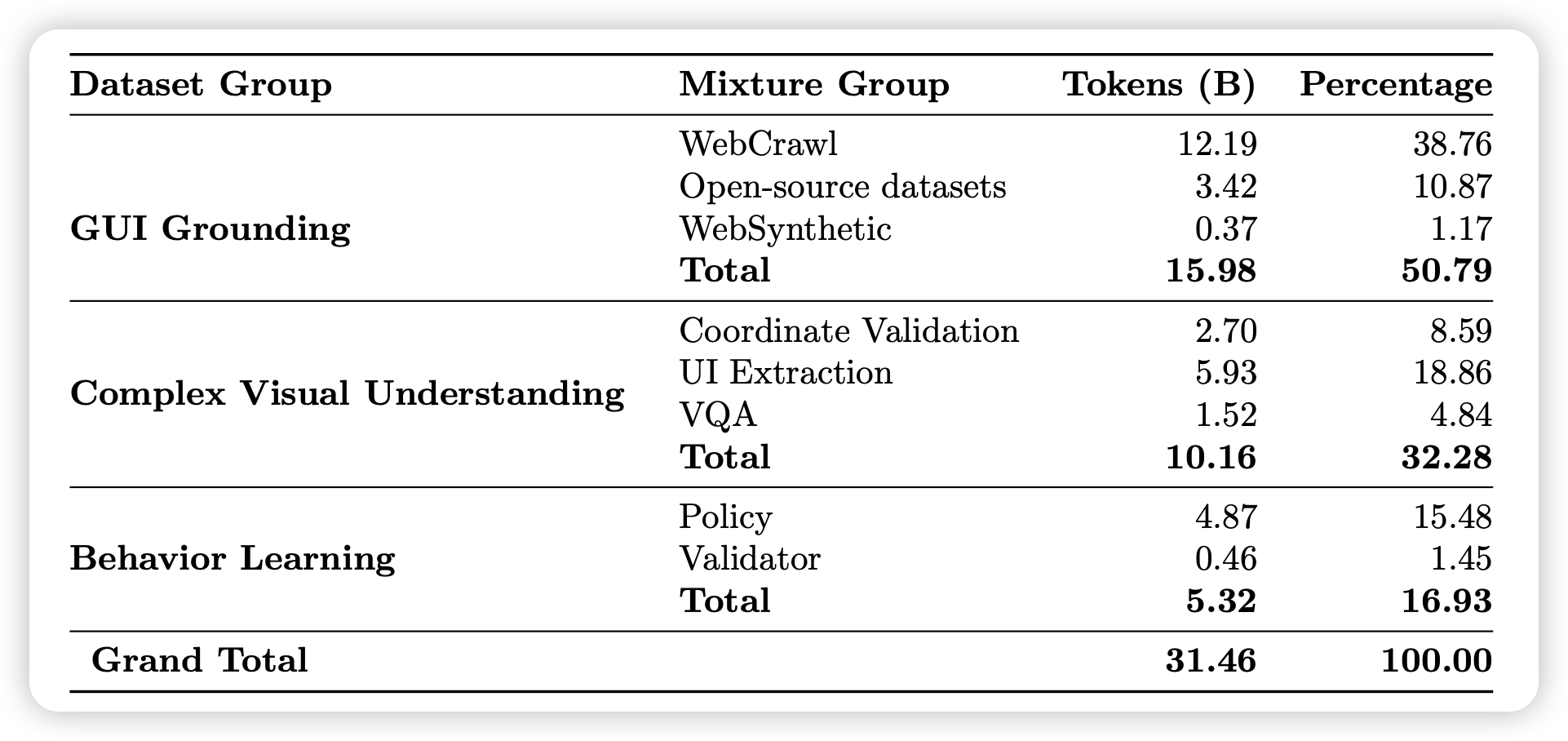
Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights
一篇开源的mid-training级别的GUI Agent工作。作者准备了30B不同场景的token做了大训练,然后在下游做了优化
The Limits of Predicting Agents from Behaviour
之前google出了一篇agent理论的工作,今天他们又出了一篇。这篇文章研究的问题是:强的Agent系统,我们能否从他的行为中推测他做决策的意图,进而预测他在out domain场景下的表现?在这个问题上,作者的结论比较悲观