MAmmoTH-VL: Eliciting Multimodal Reasoning with Instruction Tuning at Scale
一篇行文比较顺畅的工作,作者找到了学界已有的153个数据集,一个个核查了一下质量,然后再找VLM标注了一遍cot,再找另一个VLM核查了一下thought正确性,最后生成了一波sft数据,足足12M qa-pair,训了可以涨分。
STaR还在输出……

Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling
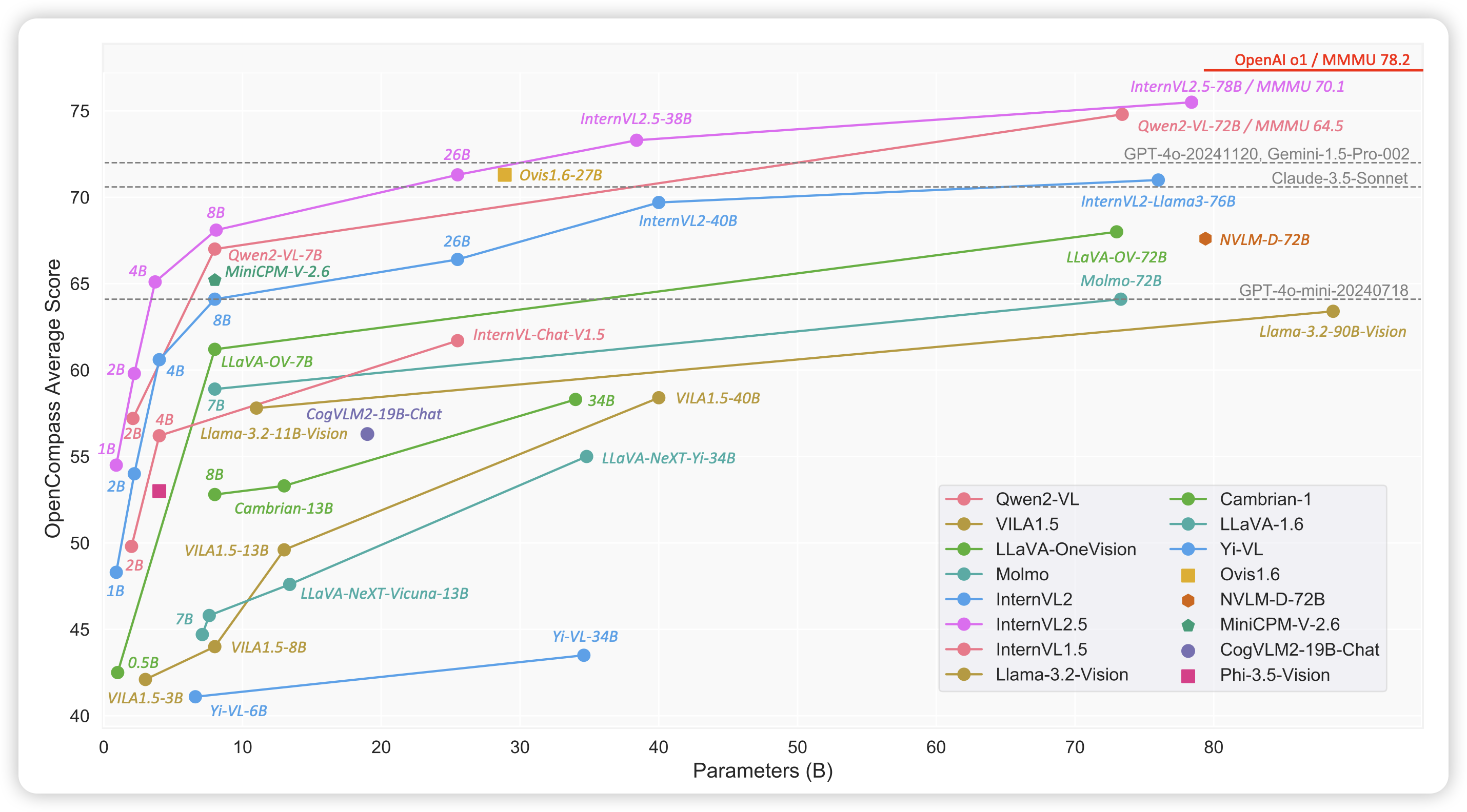
internvl-2.5的技术报告,作者直接一口气把MMMU刷过70分了,朝着o1狠狠迈进。话说我一直没怎么关注intern vl,都在关注qwen vl系列,intern系列一直做得也挺不错的
CompCap: Improving Multimodal Large Language Models with Composite Captions
meta的数据集工作,别的不说,开源数据我就点赞。这篇瞄准的叫composite image,就是之前大家说的dense-text场景,各种渲染出来的、带有文字的图片。作者构造了高质量的composite image caption pair,发现用118k caption训出来的模型,在下游任务能涨分。
虽然但是,涨点好像不太明显来着……估计没报告qwen-vl就是因为qwen已经做了这件事吧……
