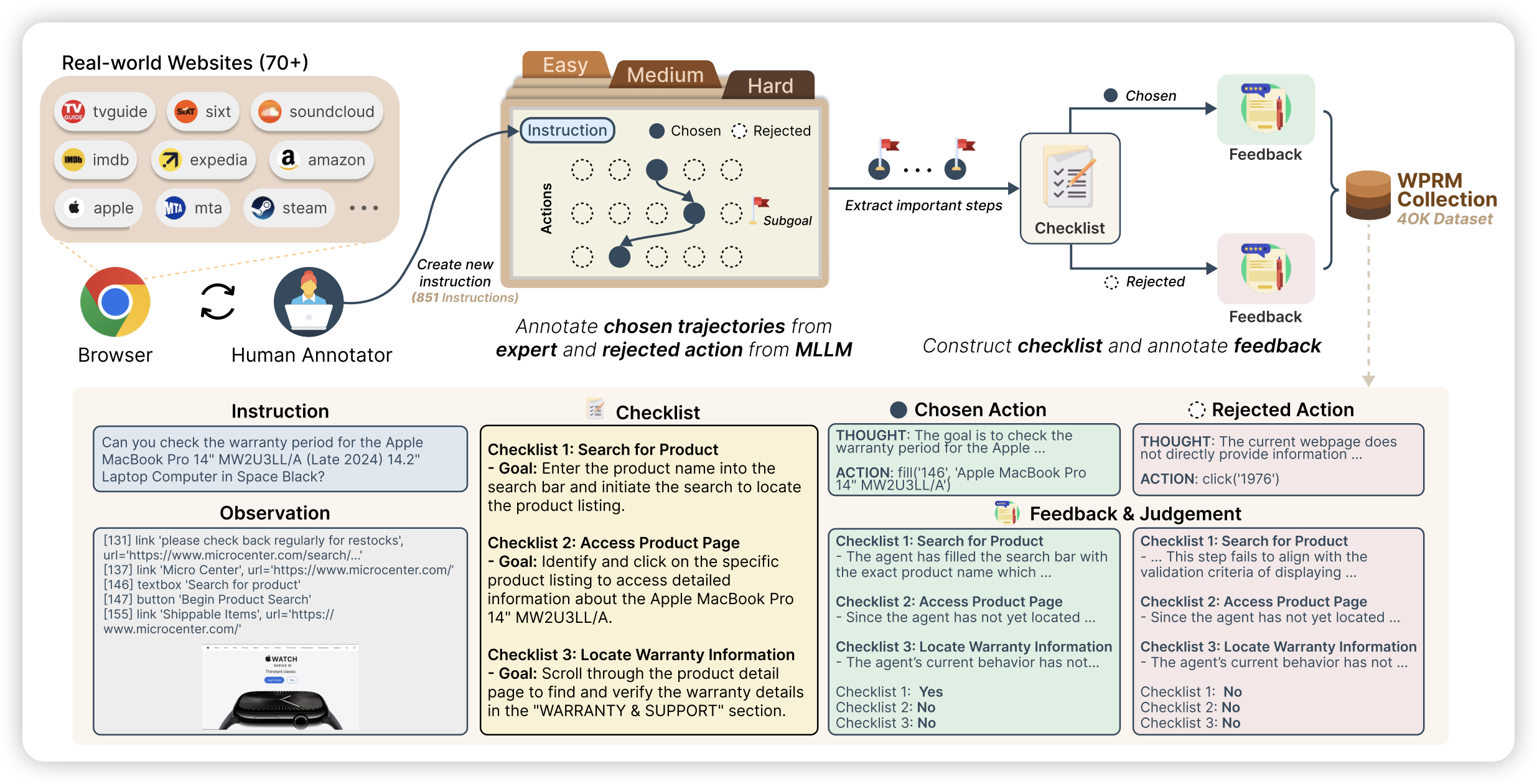
ARPO: End-to-End Policy Optimization for GUI Agents with Experience Replay
我不确定这是不是我看到的第一个跑通GUI Agent end2end rl的工作,这篇工作里作者直接在osworld测试集做训练(减少对rm的依赖),然后对train reward做出了正收益。
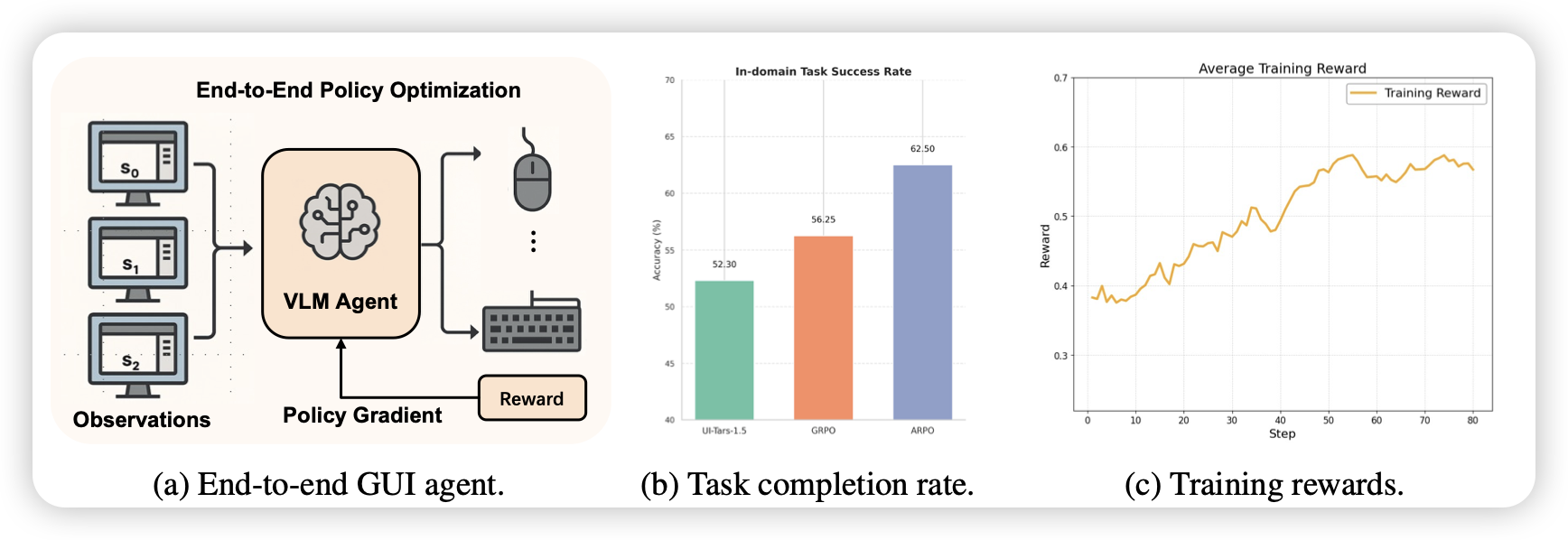
WEB-SHEPHERD: Advancing PRMs for Reinforcing Web Agents
前几天有个AgentRewardBench,测试Agent场景的ORM水平。今天出来了个Web-Shepherd,具体在webAgent场景评测PRM水平