这周是顶级,好像刷新了一天更新论文的最多纪录……今天还有kaiming神的论文,但我看了半天没看懂,就不献丑了w
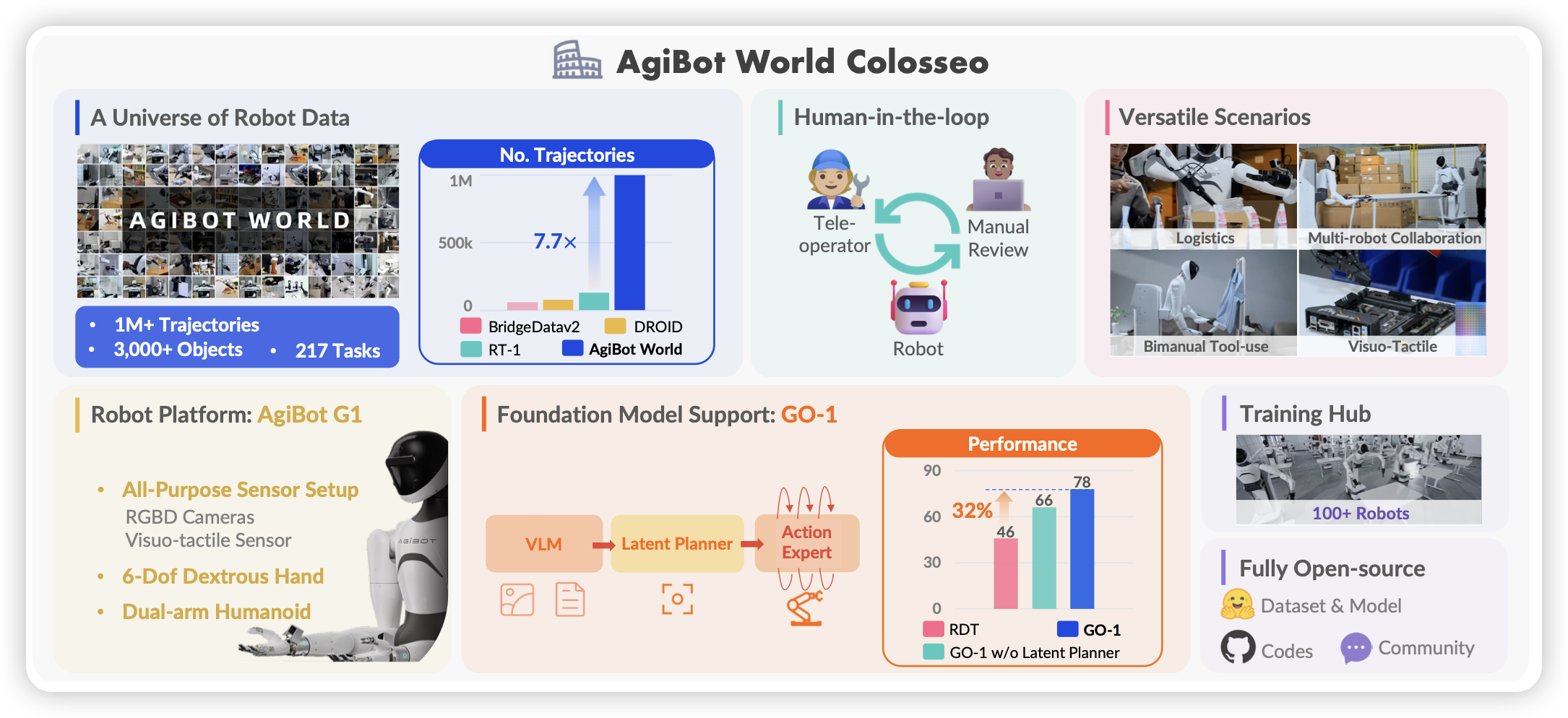
AgiBot World Colosseo: A Large-scale Manipulation Platform for Scalable and Intelligent Embodied Systems
AI Lab的具身工作,一言以蔽之:数据模型都开源。作者用human in the loop的方案,足足收了1M trace。
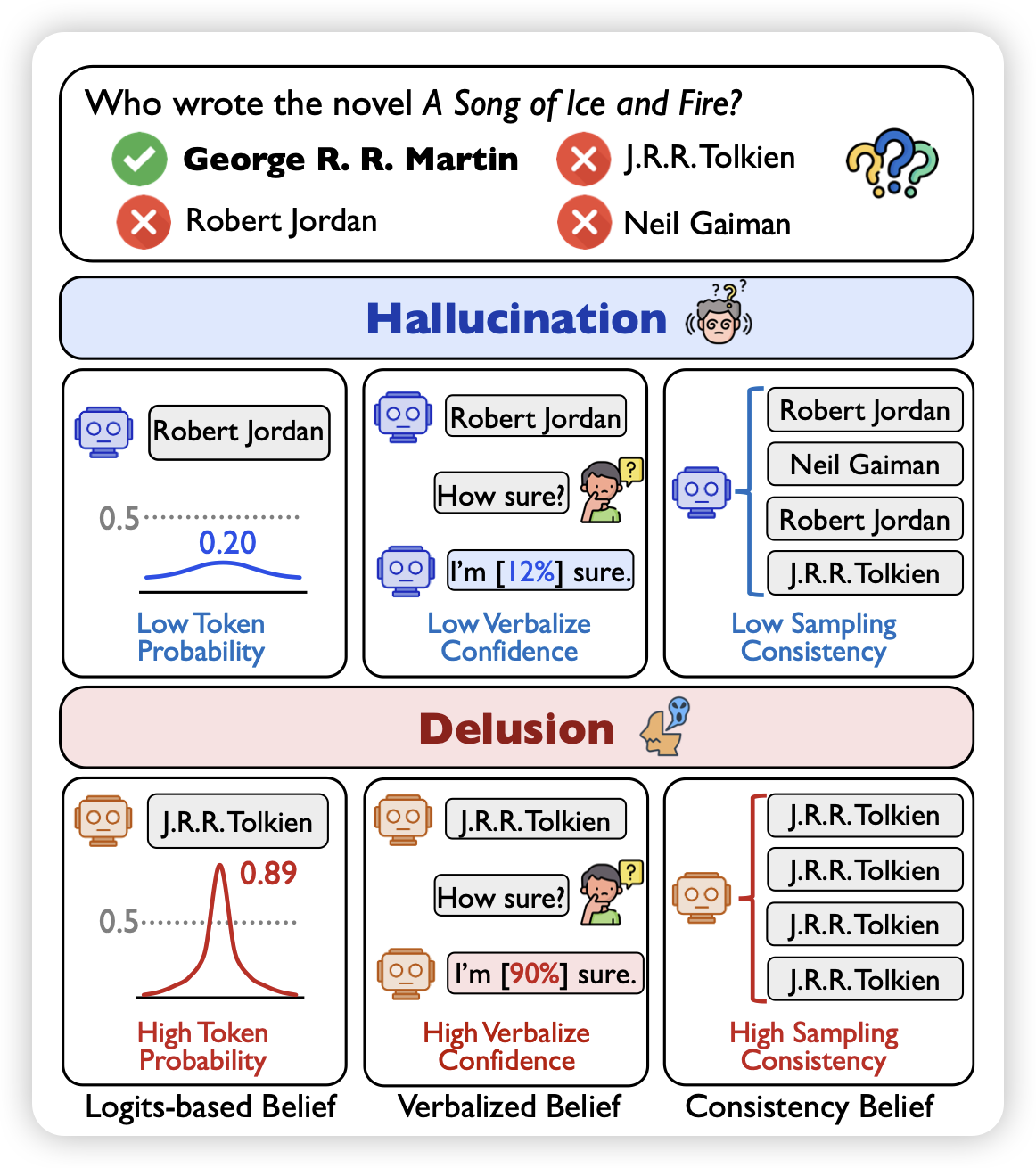
Delusions of Large Language Models
作者发现,传统hallucination检测相关的工作,有一个基本的假设在于:幻觉的地方模型的ppl一般都大。但是,作者发现了另一种现象,有些情况下,模型在幻觉,并且非常肯定自己的判断。作者把这个现象叫做delusion。作者做了一些实验,发现这些东西基本是sft都按不回来的。
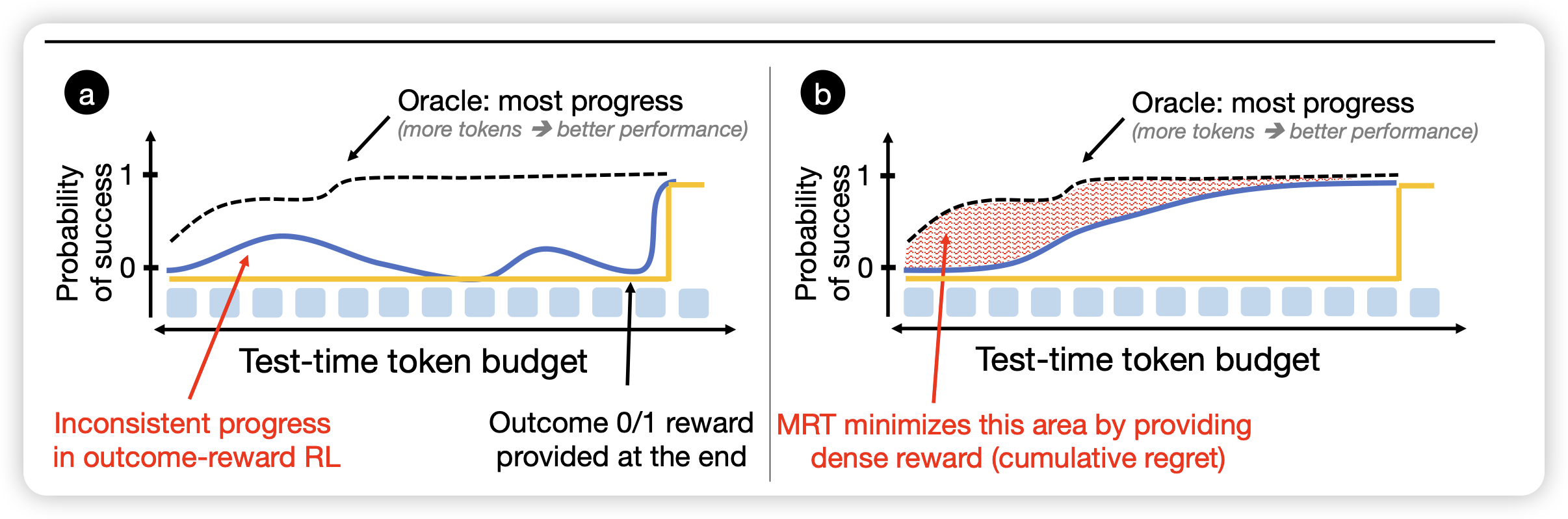
Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
Kumar带着它的奇思妙想回来了,作者发现,已有的rl算法其实没有incentivize test-time-training,而是在优化最终的绝对效果。具体来说,假设有个真实reward,随着token去成长,其实这个曲线的导数最大/而不是绝对值最高的地方是应该被奖励的,所以作者定义了一个叫做cumulative-regret的概念去优化这个东西,并希望观察是否会incentivize更好的testtime-scaling
标题里这个meta用得还真贴切,别人都是incentivize thought,他是incentivize incentivize