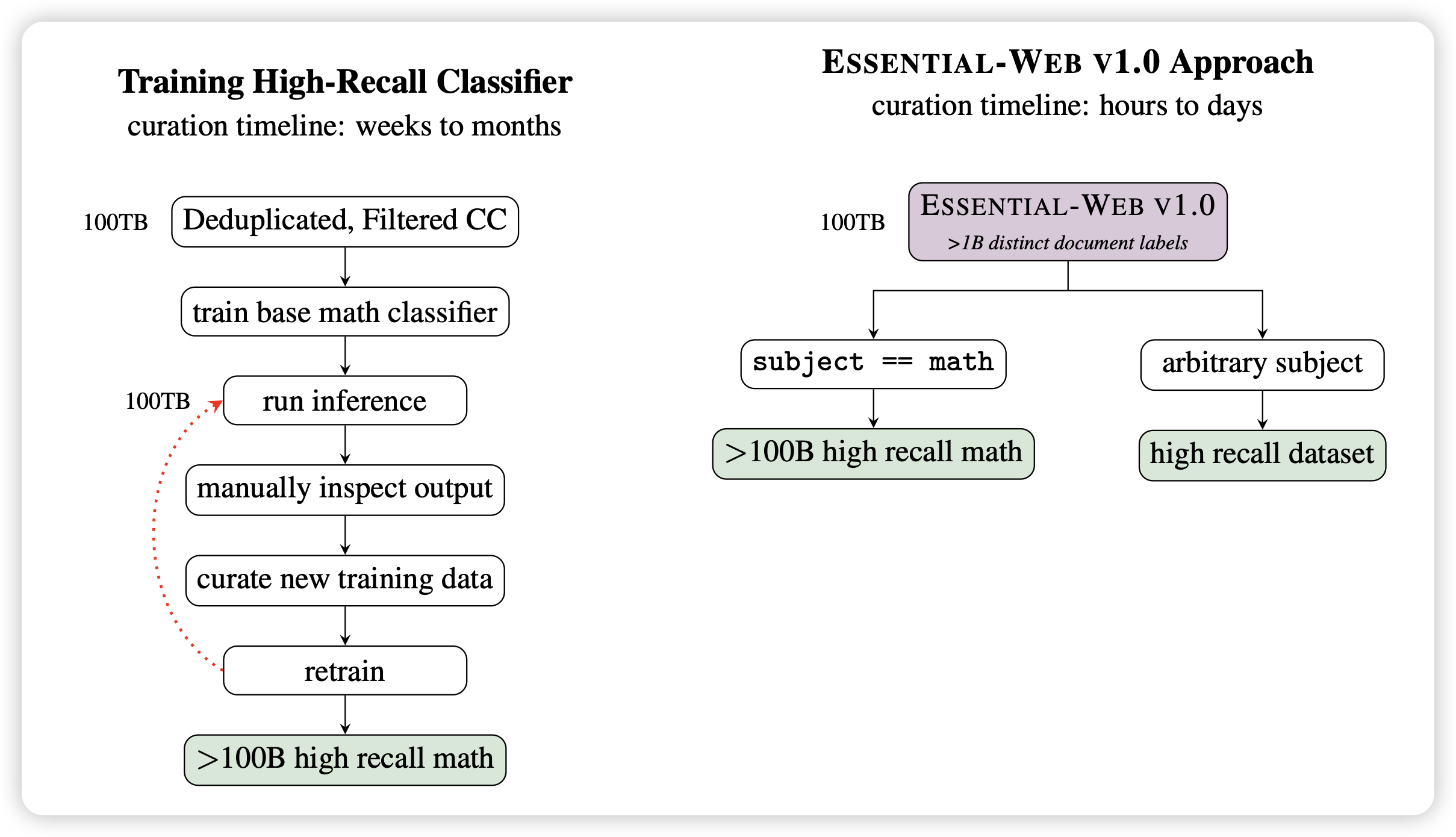
ESSENTIAL-WEB V1.0: 24T tokens of organized web data
作者发现:随着时间增长,各家大模型公司的预训练数据量是指数增长。所以花在data filter的时间将会越来越多。所以作者构造了一个通用的筛选后数据集,提前针对不同的维度提前打好标签。这样在用的时候,直接根据数据标签做sql筛选就行了
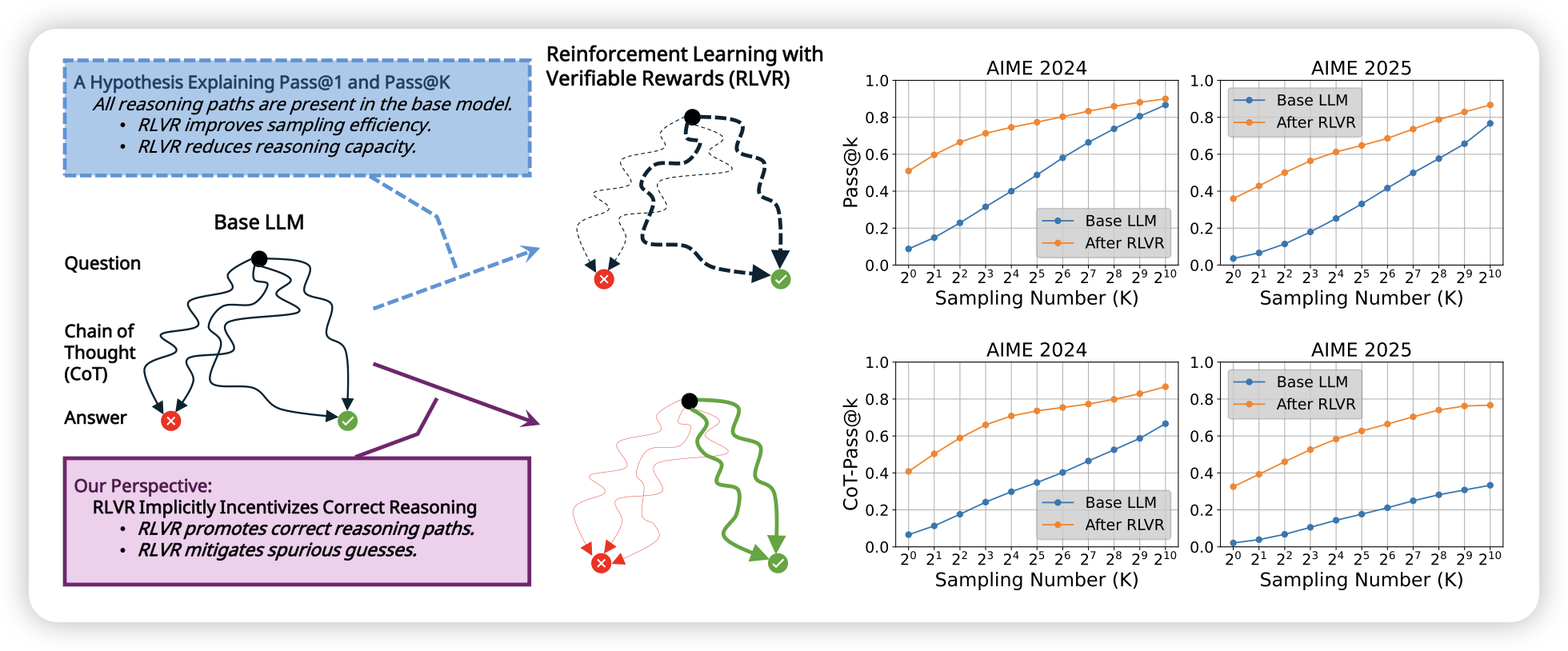
Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs
这篇工作是对之前一个工作的回击:之前有篇工作发现,RLVR并没有使得模型的bon提升。这篇工作指出了一个关键问题:bon这个metric本身是有问题的,因为bon的答案很可能是假阳(答案正确,但思考过程错误)。作者用另一个llm verifier检查thought是否有错误,发现如果考虑这个因素的话。新产生的metrics,训练了rlvr后是大大提高了
话说我之前看到那篇工作,是感觉会不会是训练后entropy关闭了,导致bon在行为上和bo1差不多……