DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
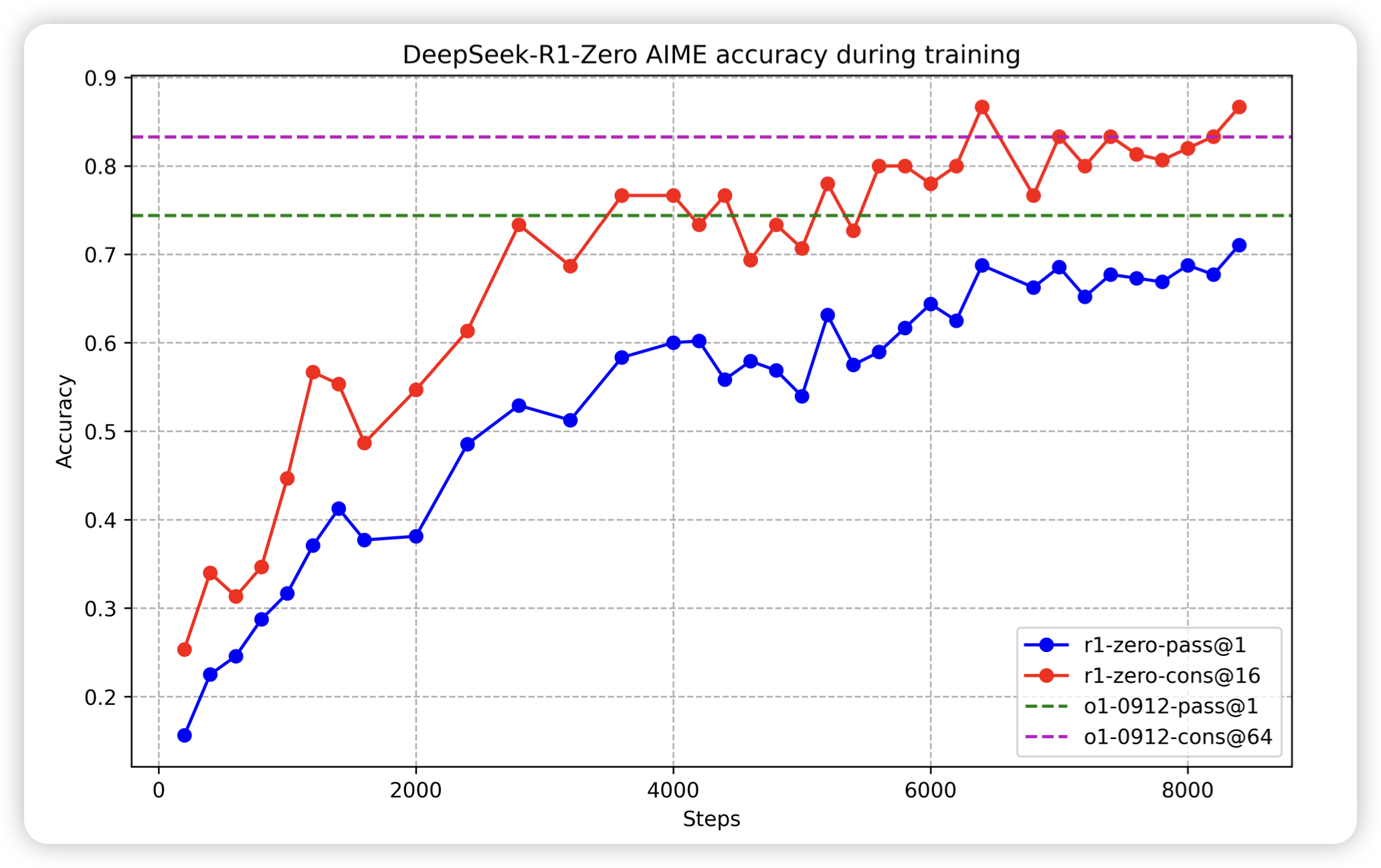
r1这张图有希望成为今年AI圈最火的图。deepseek做了一套cold start的o1训练,可以在不使用o1-like sft数据的情况下,从0激发出o1 thought。这个点感觉是目前只有r1(当然还有o1自己)做到了。但是对于训练数据的prompt set,报告里语焉不详。
他都开源了,你还要要求什么呢
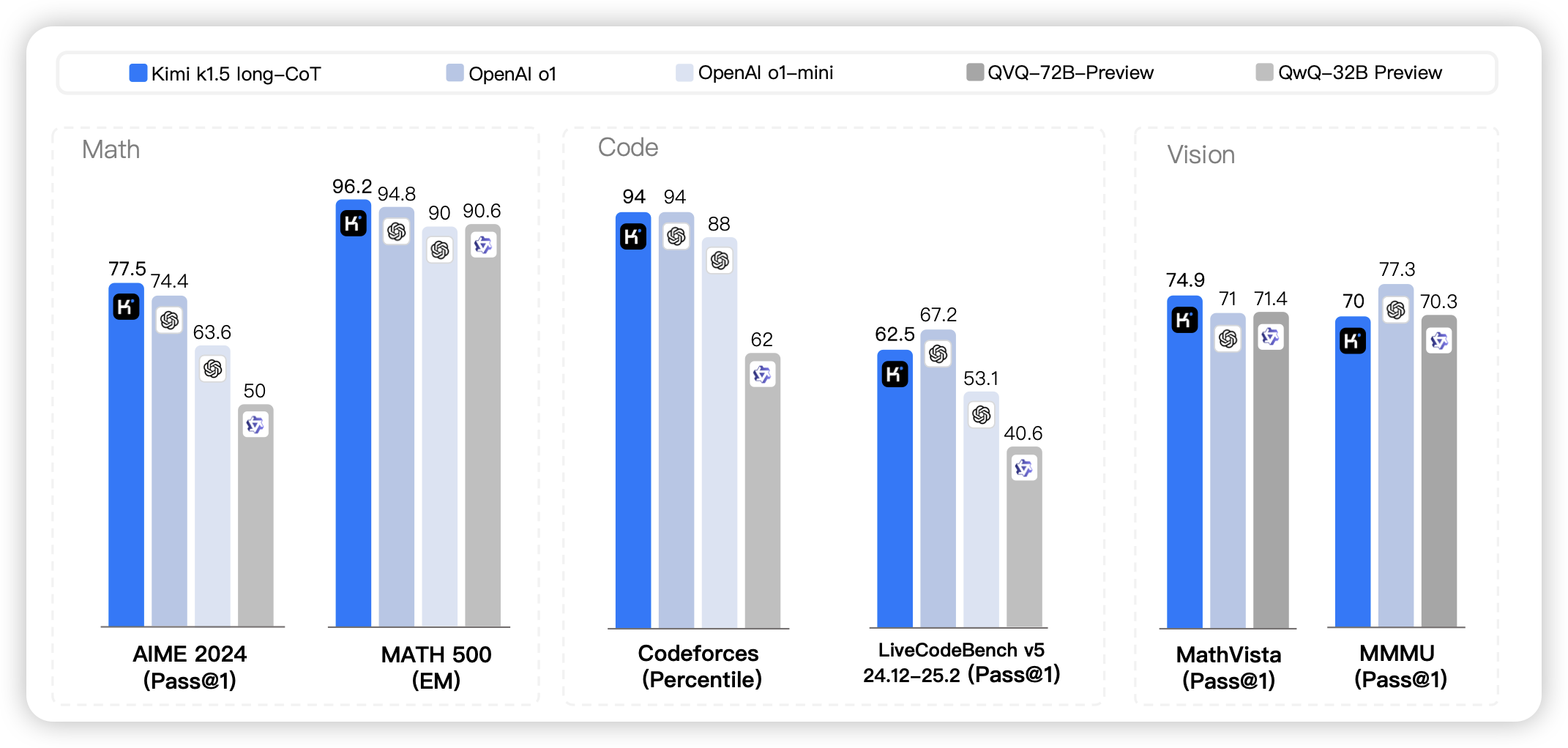
Kimi k1.5: Scaling Reinforcement Learning with LLMs
kimi出的o1模型,发布时间和r1一起,但是好像在twitter的传播度远远不如r1。k1.5直接支持了多模态的推理,另外还涉及了一套把long thought缩写成short thought,由此蒸馏短模型的方案。
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
达摩院新的VLM,这次训练数据量拉满了。最后的效果也很好
