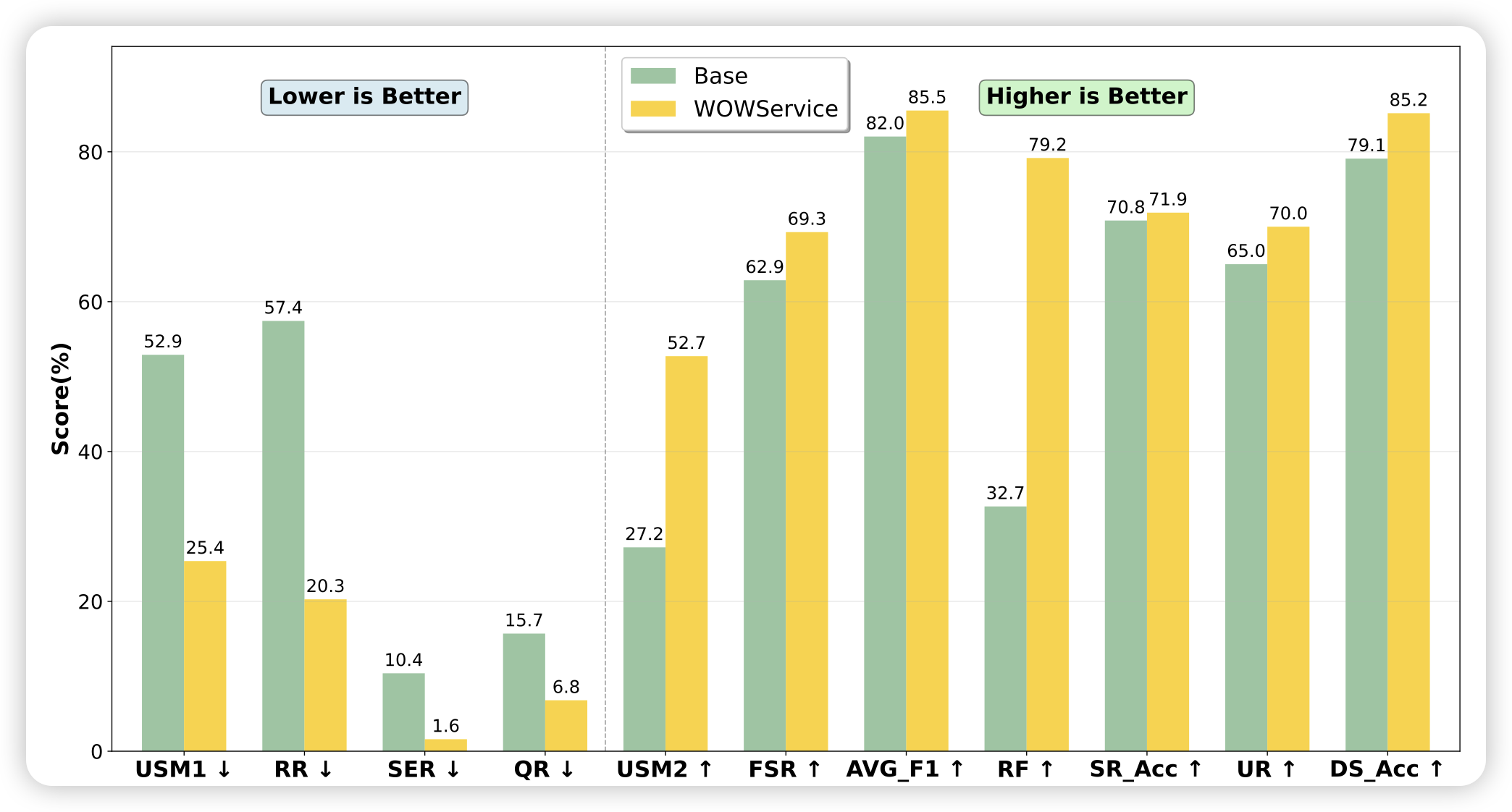
The Art of Scaling Reinforcement Learning Compute for LLMs
大家说RL手法对的话,可以”一直训一直涨“,是真的吗?meta这个工作用40000 gpu hour帮大家画了曲线。作者甚至给一个8B模型挂了10000gpu hour的算力
之前nvidia做过几个对超参的大规模消融,这篇工作来了个对训练规模的消融
AceReason-Nemotron 1.1 Scaling Up RL
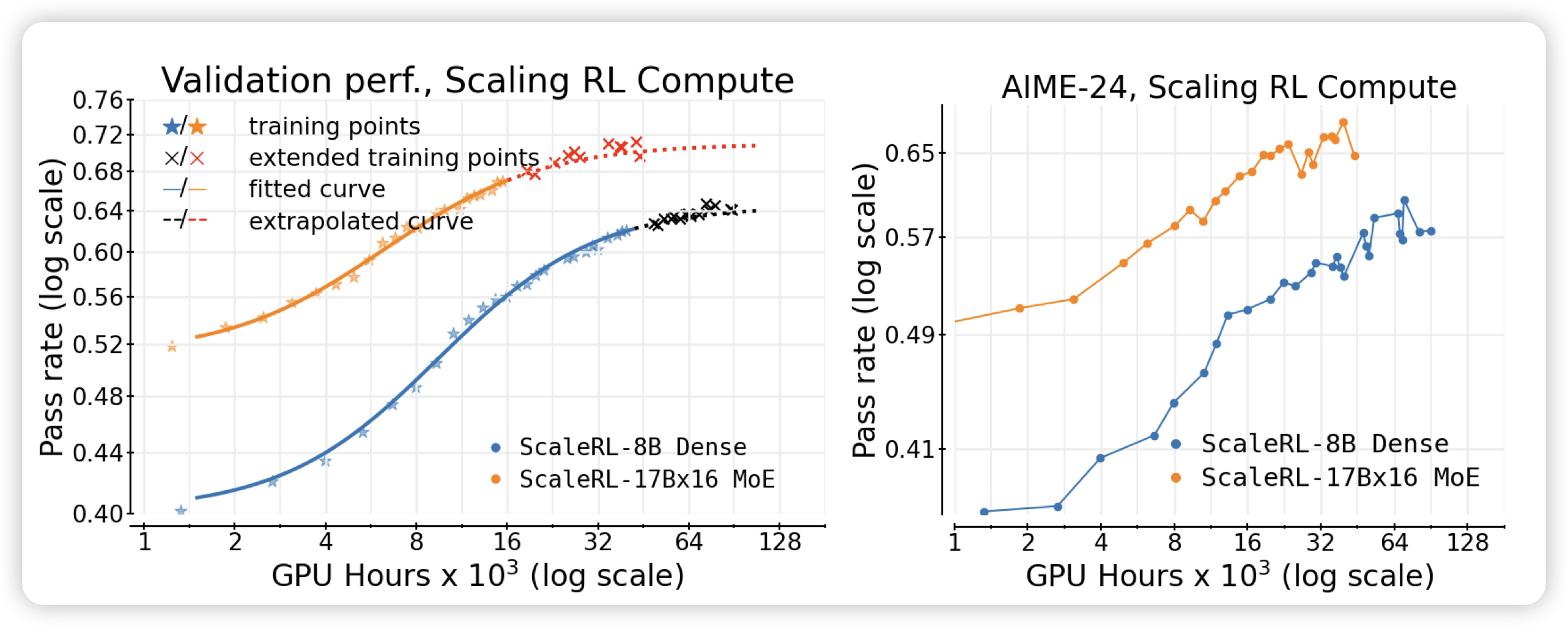
Higher Satisfaction, Lower Cost: A Technical Report on How LLMs Revolutionize Meituan’s Intelligent Interaction Systems
美团的一个工作,作者直接搬出来了一套ai system,然后测试了AI系统对于实际线上服务的各个场景的收益。