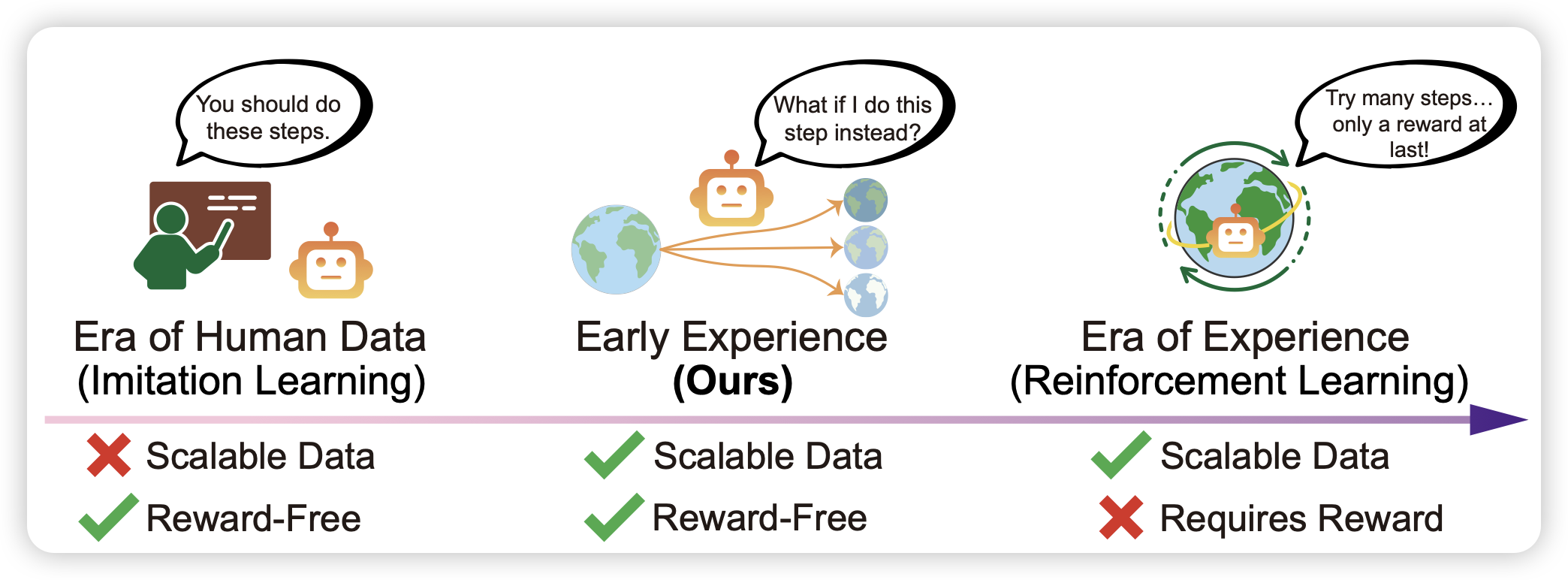
Agent Learning via Early Experience
作者发现:正常的rlvr需要准确的reward,但这个东西其实并不scalable,而且需要做很heavy的、带环境的rollout才能获取一次reward。但是实际上,和环境的交互本身是不是有价值呢?作者认为,agent traj中产生的每一次环境反馈都是有意义的,如果模型能预测这些东西,可能对完成任务有帮助。作者发现,直接通过rollout+预测env的模式,就可以让模型提升表现,或者说提升接下来的真正rl阶段的潜力
话说rl里有一个路线是cruiosity-driven rl,通过对环境的预测误差决定模型的reward。有点像这个框架的一个“更active”的模式