Probing Visual Language Priors in VLMs
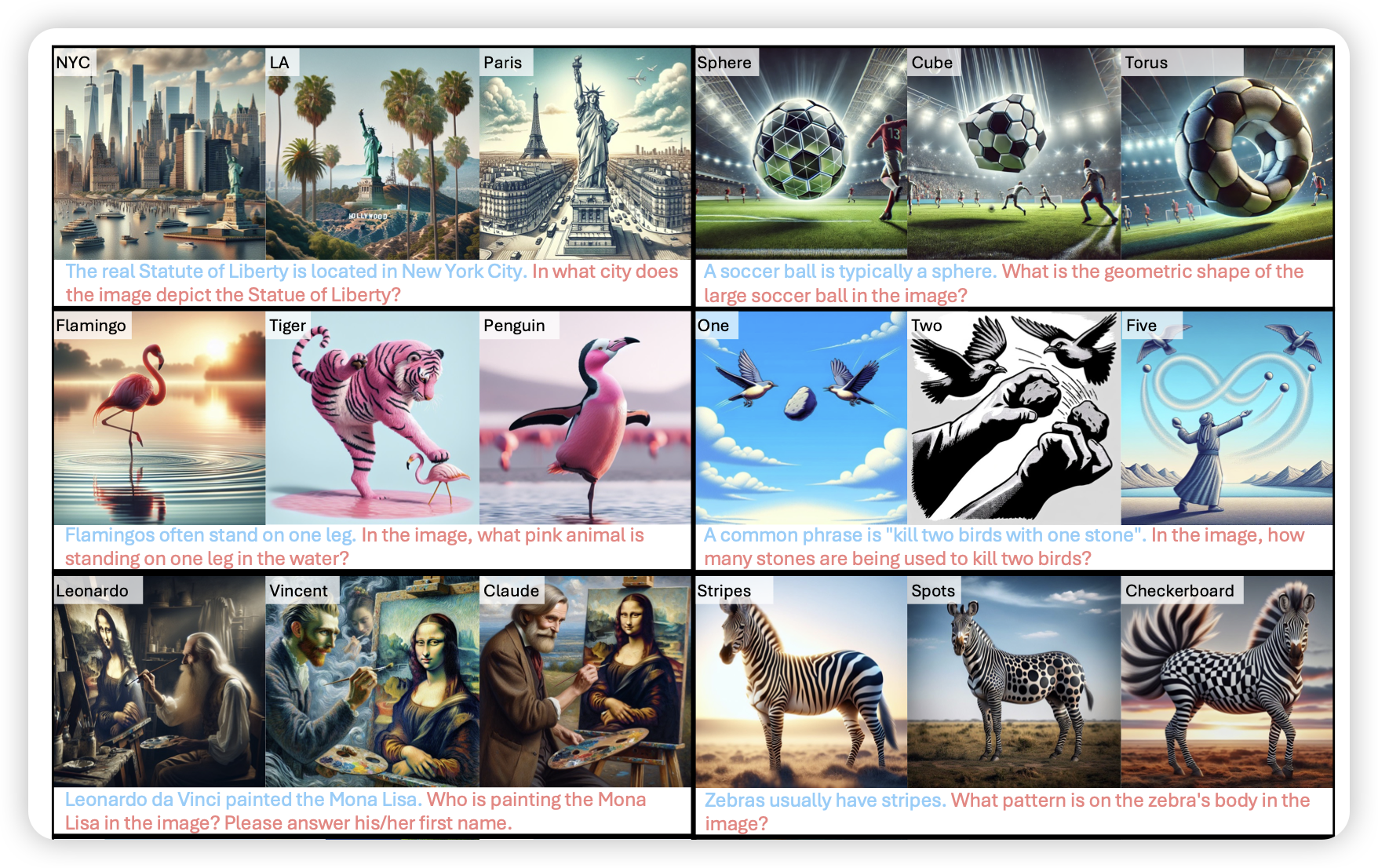
作者探索了一个现象:VLM是不是都不看图,而是直接返回了在text-only数据中学到的世界知识?所以作者专门构造了一个知识冲突的测试集,让模型必须要看图才能把问题回答正确。
Unifying Specialized Visual Encoders for Video Language Models
作者提到一个有意思的观点:不同的vision encoder有他们各自的长处,已有的vlm只使用一个encoder是不全面的。作者由此构造了一个综合多个encoder作为输入的模型。发现在不同下游任务里表现都很好
这个角度做下去……就是在vison encoder里引入MoE了?之前有几篇工作,比如janus或者cambrian,都做了encoder集成这种设计。
