In-Context Learning Strategies Emerge Rationally
goodman的工作,作者在试图解释in-context learning行为随着训练的变化。如果大家之前看grokking方向,就知道里面会提出两个回路:
- 背诵回路,记下所有问题的答案
- generalize回路:学到原理,然后更好地泛化
作者发现,在训练初期,其实是generalize回路占主导(可能因为他对参数更新的要求更小),但随着训练,逐渐变成背诵回路占主导。因为generalize回路可能没法完全解释所有的特例。作者甚至发现,用一个简单的贝叶斯拟合,即使只有3个参数,就可以高准确率地预测出回路"退化"发生在什么时候。
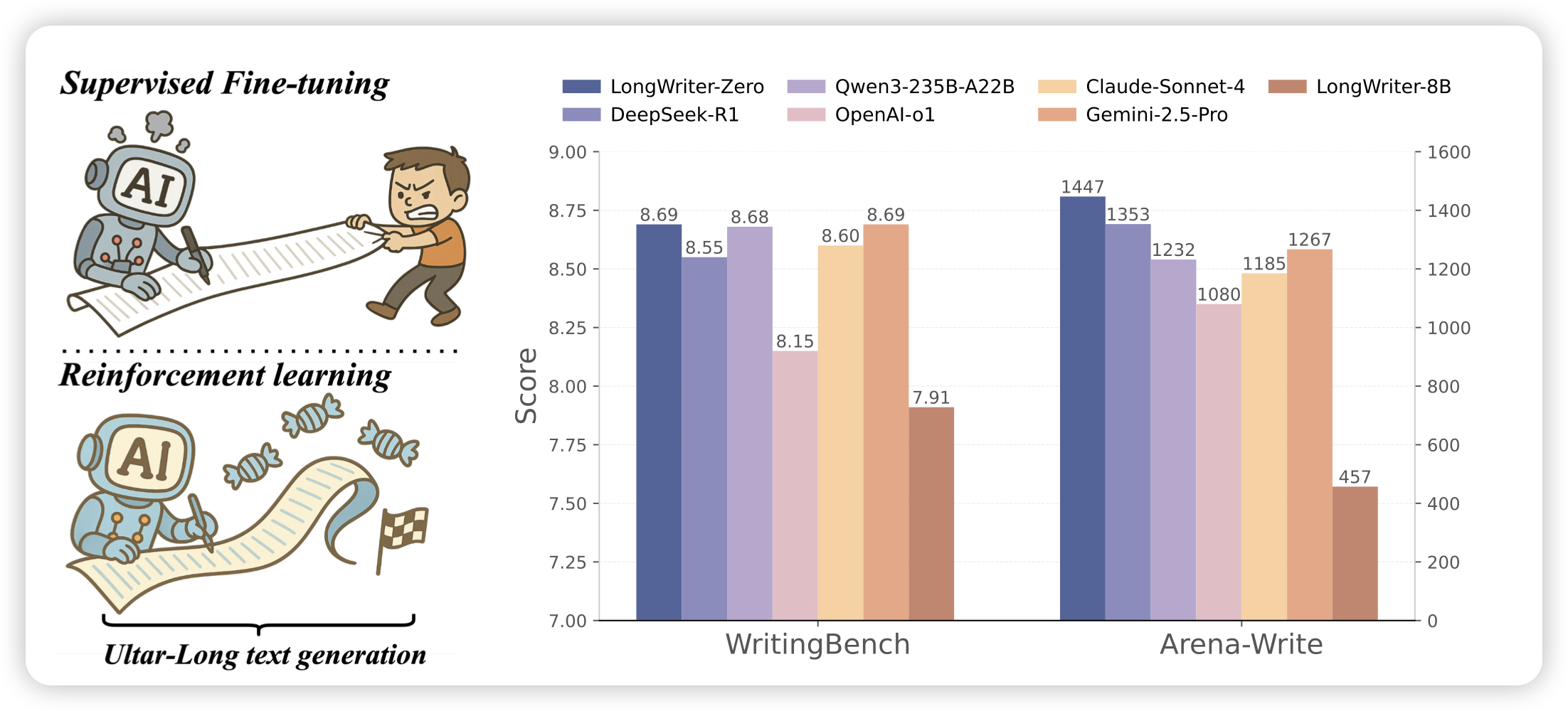
LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning
lijunzi的老师的工作,是超长文本生成。这是一个类似r1-zero的工作,作者在pure-rl setting(没有冷启数据)下,把qwen 32B的分数训上去了
话说我一直感觉,ultra-long这个setting应该建模成agent setting,就是给一些plan工具之类的来多轮搞