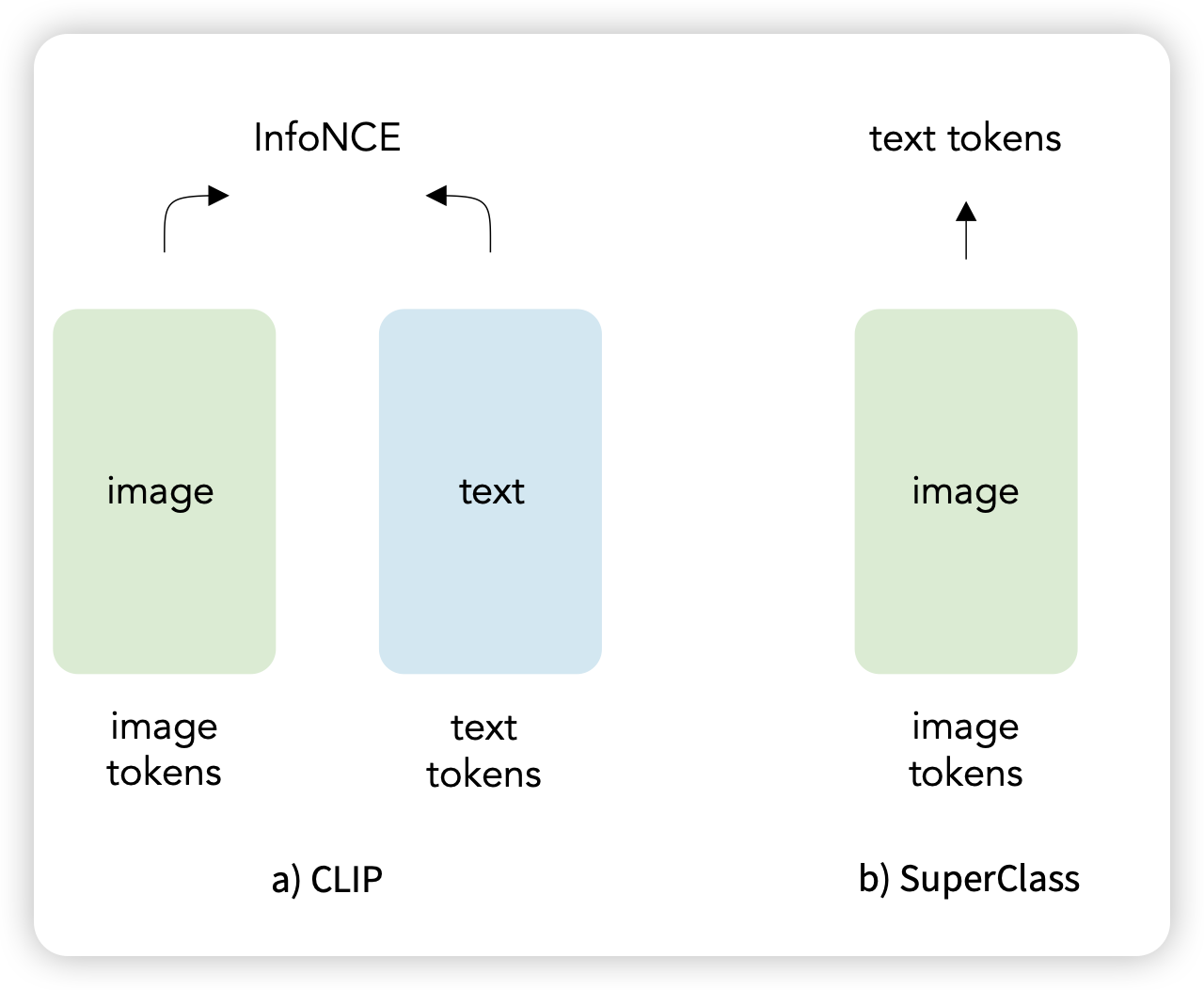
Classification Done Right for Vision-Language Pre-Training
z字节的工作,昨天出了rar,今天又来一手。作者提了一个巨简单的方法:如果有了image-caption对,直接把caption里面的token去掉position后当做bag of word,变成一个把图片到词表空间的分类任务会怎么样呢?作者发现,这个loss的效果甚至很好。
why? 所以一切都是yolo……
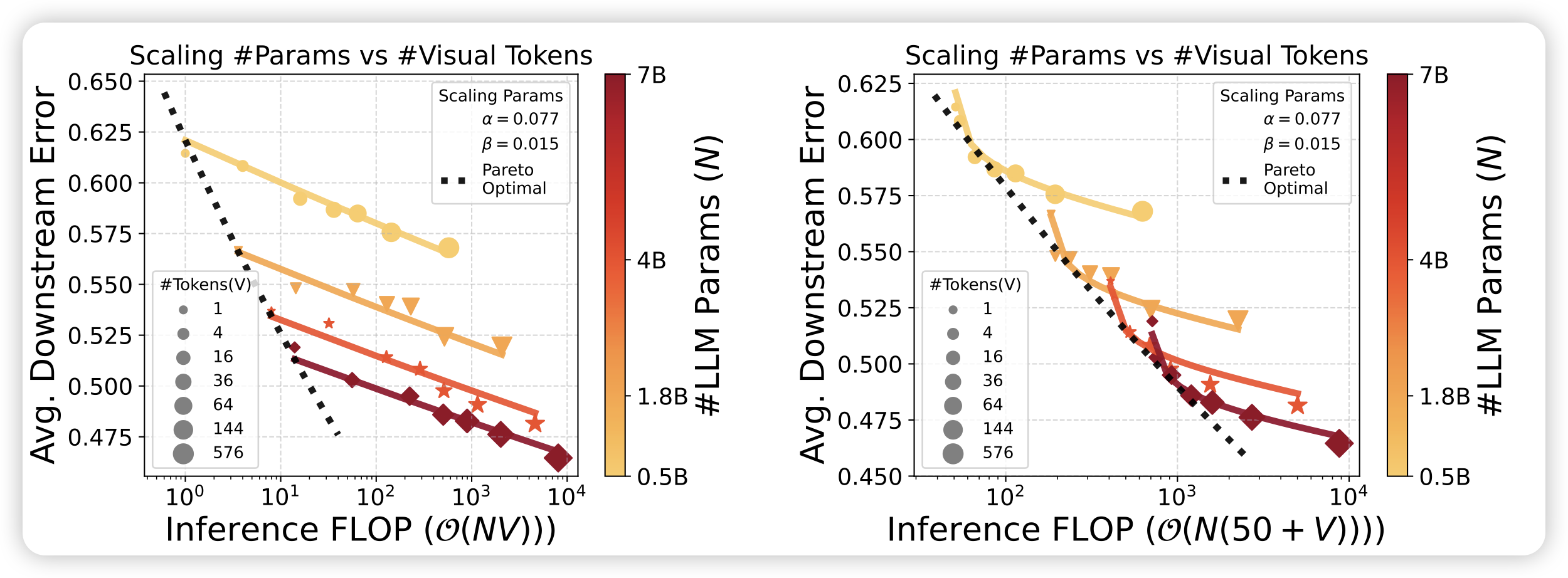
Inference Optimal VLMs Need Only One Visual Token but Larger Models
一篇研究VLM inference optimal的工作,作者探索了在同样的FLop下,应该选择大模型,少image token;还是小模型,多image token。通过实验,作者发现不管budget开多大,总是大模型的效果倾向于更好。
这是不是代表着,目前的模型都没有特别认真的去看图像信息……