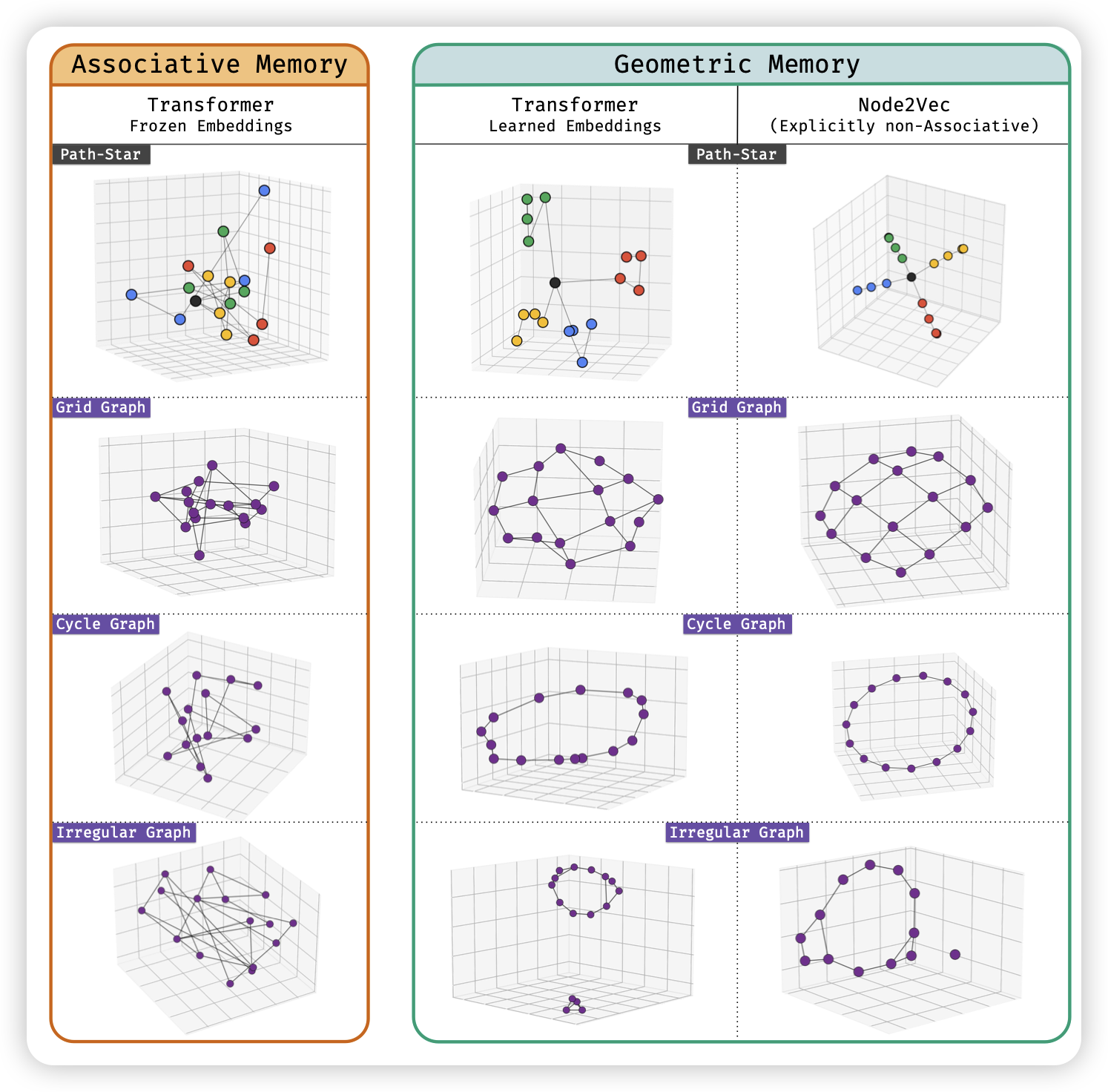
Deep sequence models tend to memorize geometrically; it is unclear why.
这是一个偏理论的工作,但实验设计很有意思。作者想要区分:模型的记忆,是类似于查表的结构(k->v),还是类似于embedding相似度匹配?作者设计了一个场景:给定一个复杂的树结构,要求模型给出两个点之间的唯一路径。输入里是类似于(a-b, f-g)这种连接关系。
- 如果是传统的in-context learning 模式,那没有办法做出来,靠memory的话,这就是一个\(O(e^n)\)的事情
- 但作者把这个任务改成了training based。固定一个50000节点的图,让模型训练去预测一些节点的路径。此时,模型用几何模式和kv模式,对降低训练集loss其实是差不多的
此时,如果模型的记忆方式是“kv”,那在测试集上将没有任何泛化性。但是,作者发现模型竟然在测试集上仍然有几乎100%的成功率。说明图的几何结构以某种形式进入了参数里,模型可以以类似于人“瞄一眼”的模式推理。
在没有外力的情况下,模型为什么会倾向于用几何模式呢?
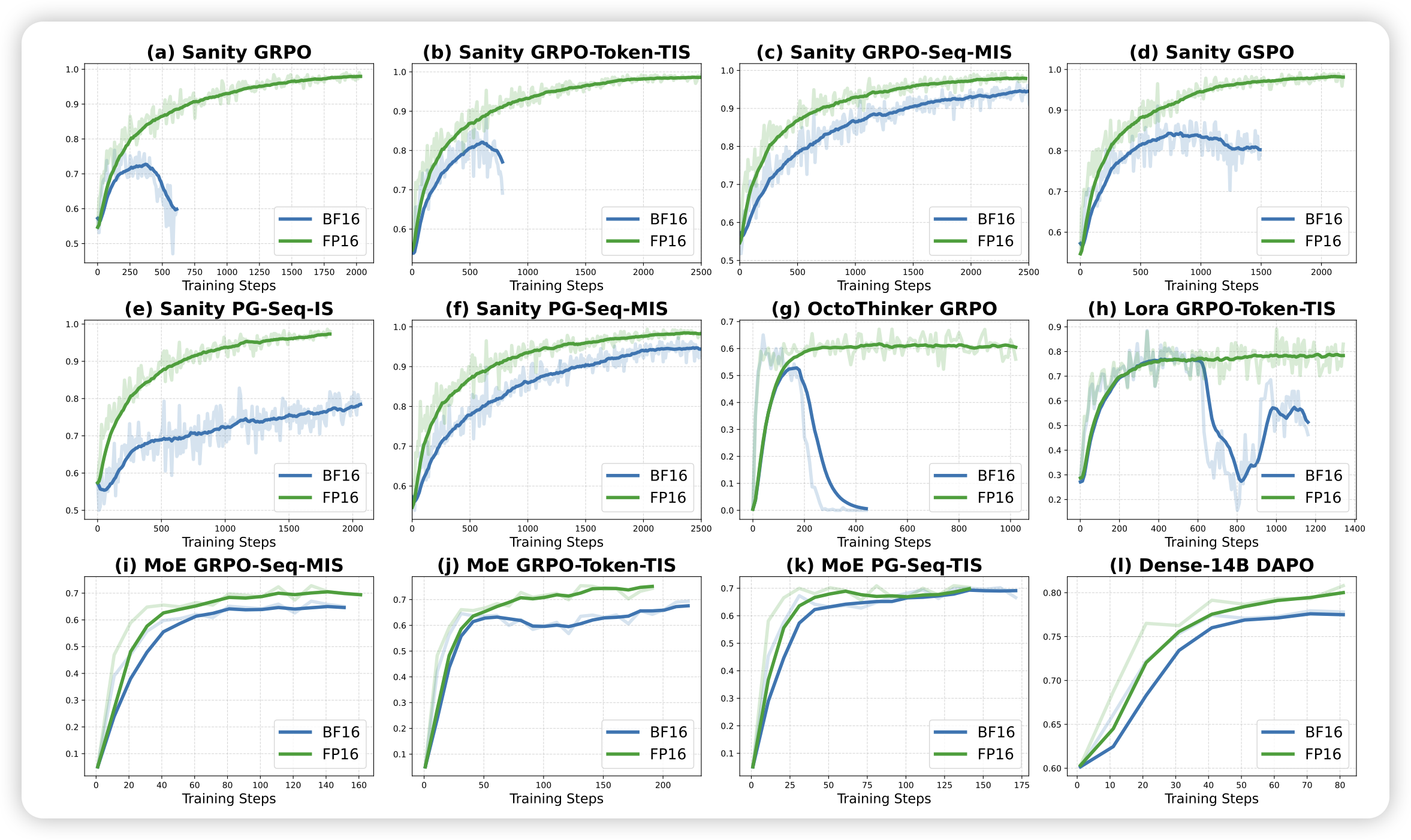
Defeating the Training-Inference Mismatch via FP16
这篇工作发现了一个惊天trick:大家一直在说的train/gen mismatch,可能很大程度上是bf16带来的。单纯把算法中的bf16变成fp16,就可以提升很多训练效果
GUI Knowledge Bench: Revealing the Knowledge Gap Behind VLM Failures in GUI Tasks
一篇cua的qa benchmark工作。这几年cua一般都是出执行类的题目,但作者分析了online benchmark的failure mode以后,发现其中很大一部分是缺乏app操作知识。所以作者把这个问题单独地建模了出来,然后又掺杂了一些visualwebbench那种perception类的题目,以评测模型综合的gui知识水平
上一次看到还不错的gui qa benchmark,是GUIWorld,已经快2年了