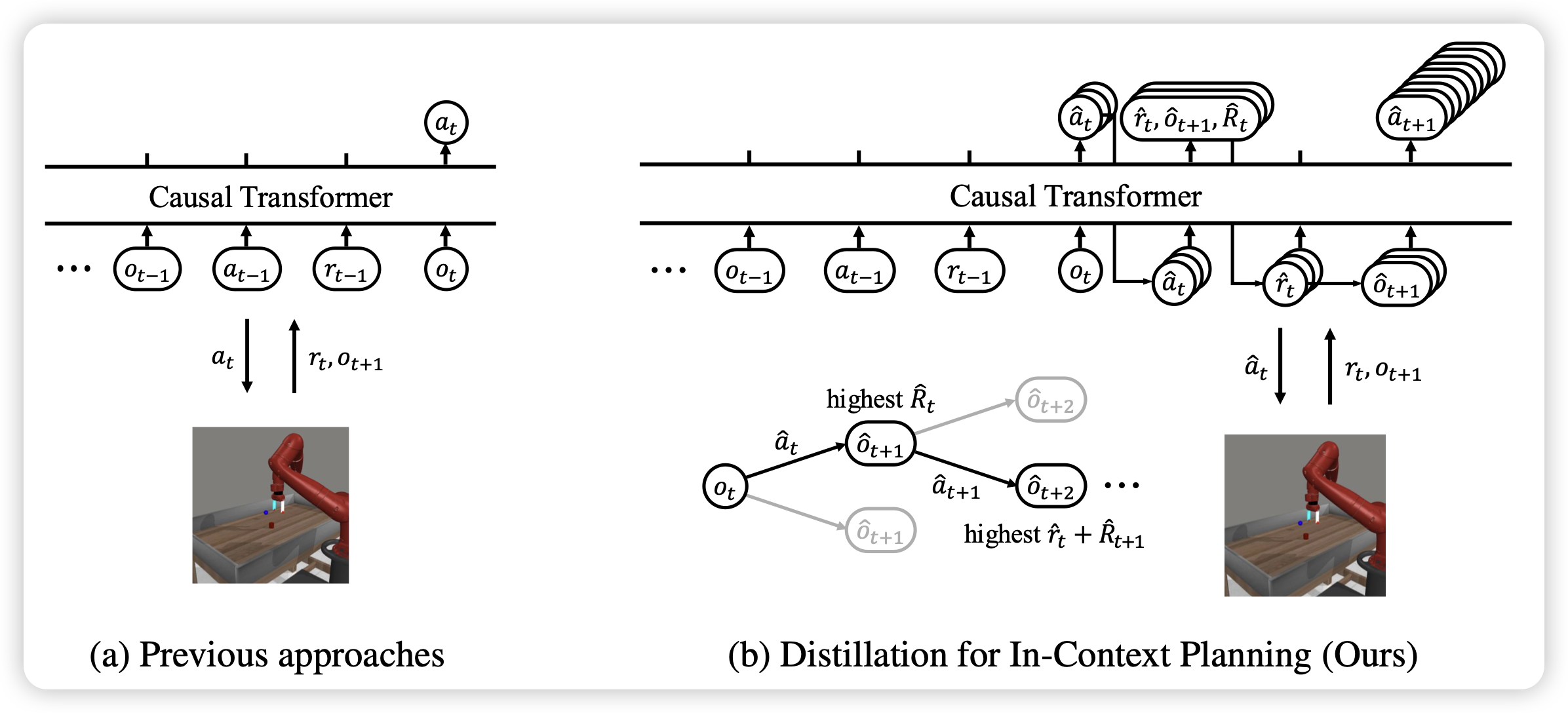
Distilling Reinforcement Learning Algorithms for In-Context Model-Based Planning
最近arxiv开始嘎嘎出现ICRL类的工作,作者发现以algorithm distillation为代表的Old School ICRL,都是直接prediction训练过程中的所有action。但是这样其实没有对rl算法中很多内在的、随训练更新的数值进行建模(比如 value,temperature等),如果让模型除了预测action以外,在预测一些rl算法运行时的侧信道信息,会更有帮助吗?作者发现有效果
不过这个观点感觉有点怪:ICRL的核心是想着减少对于algorithm的认知,如果通过耦合侧信道信息进去,好像会破坏ICRL的假设