WeGen: A Unified Model for Interactive Multimodal Generation as We Chat
这个工作很牛:作者想要让文生图模型可以天然地和用户交流,并且多轮迭代的去完成任务,这个东西本质上需要语义连贯的、含有图片的chat数据。作者从视频数据中,想办法合成出了符合要求的数据,并训出来了模型。
底下这个图整个是一个trace,感觉有点之前4o Native image generation的味道了
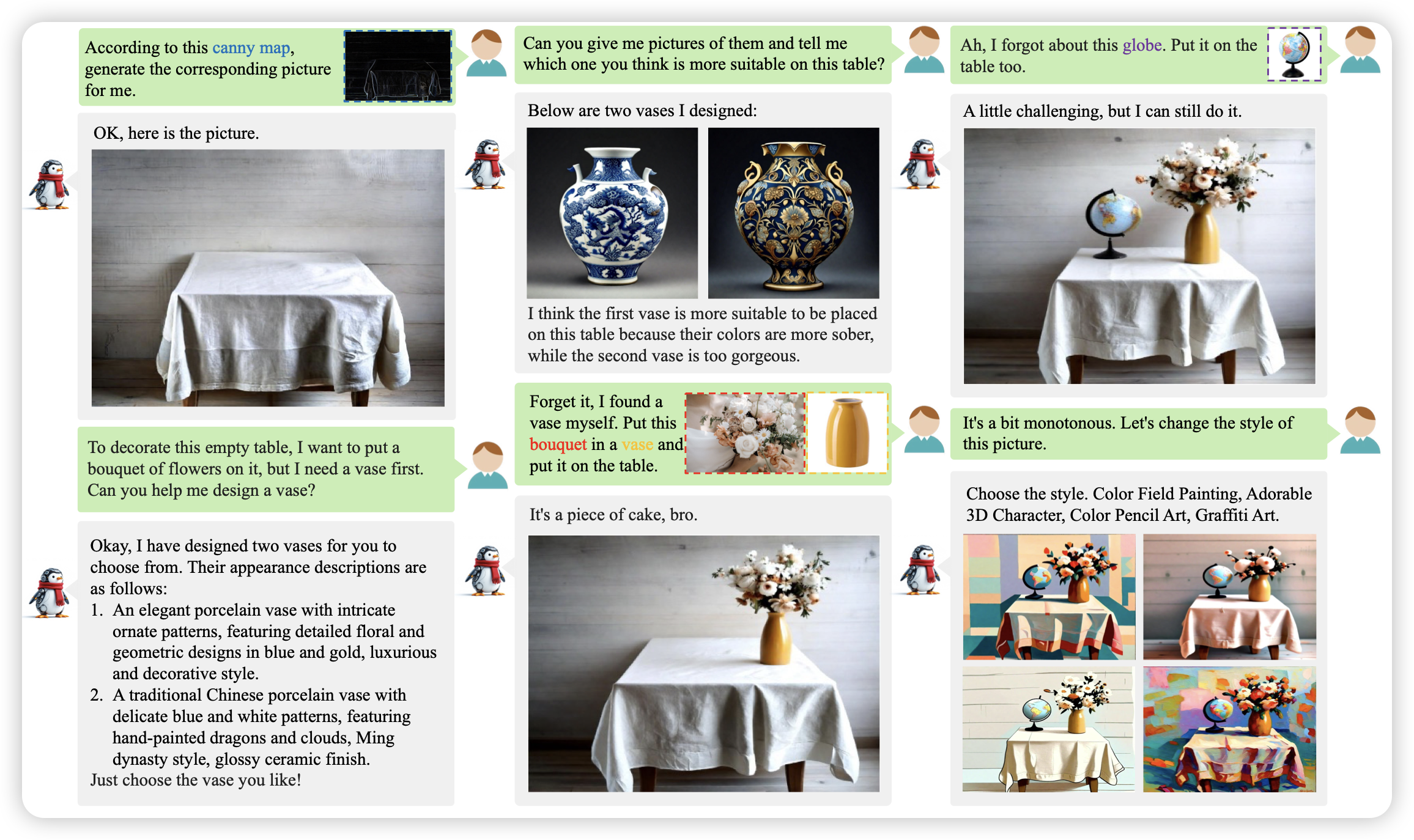
Streaming Looking Ahead with Token-level Self-reward
这篇工作挺有趣的,作者发现,模型在解码的时候,如果可以先多次解码完后面的token,再返回来给前面token做reward,就能在测试时提高效果,类似于另一种形式的beam search,只是把reward从ppl换成别的东西。
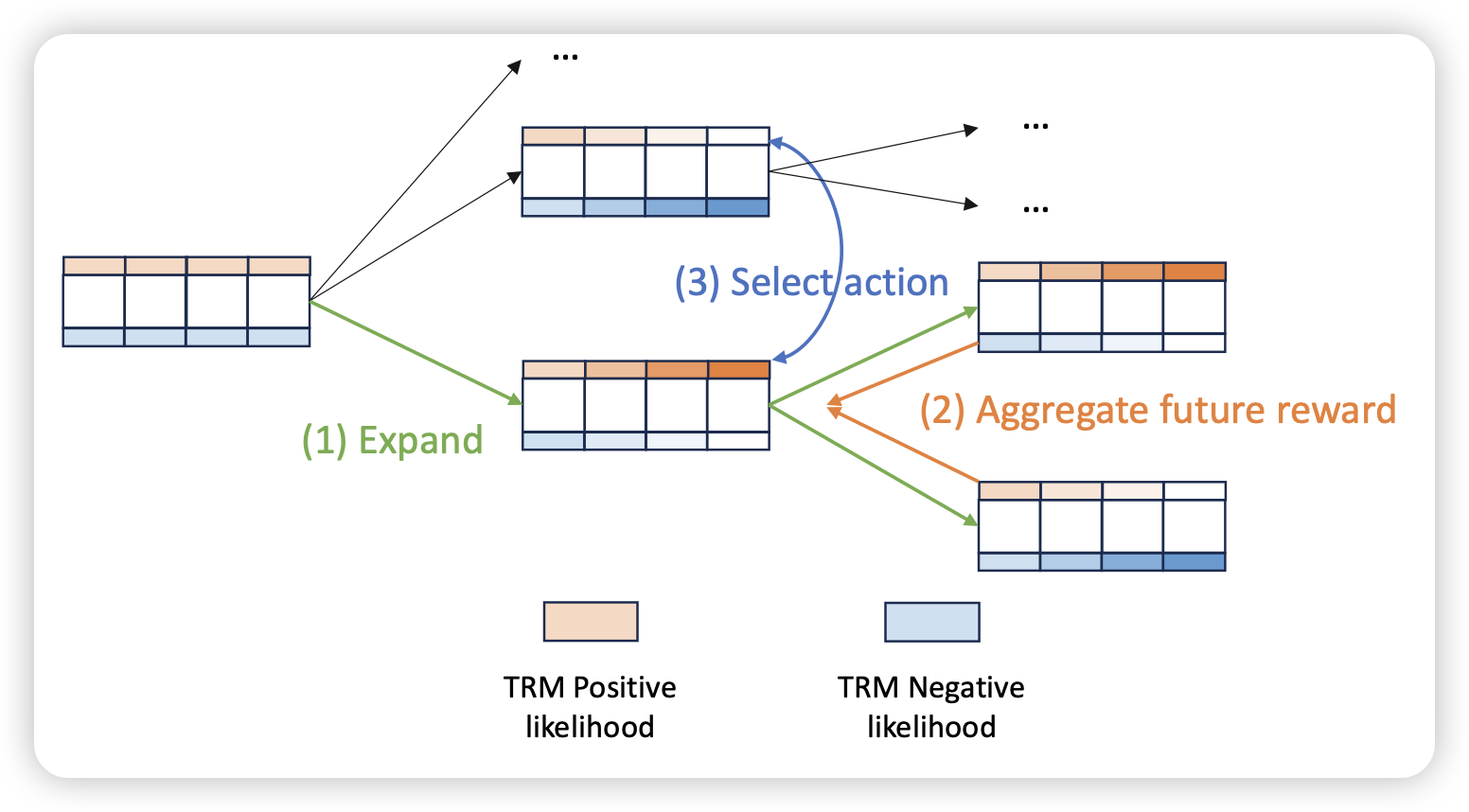
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
phi系列的最新工作,这次作者直接支持了image、audio两个模态,好像是phi系列第一次出多模态的模型?作者在保持3B的基础上,用200k词表还支持了多语言