First Return, Entropy-Eliciting Explore
Seed和MAP的论文,最近两天twitter爆款。这篇工作的思想和phi4很像:如果我在rlvr setting上有某个办法找到一些“关键位置”,那么可以用这些关键位置作为锚点,去定向做一些mcts。然后就能拿到一个胜率随锚点的变化,这个其实是现场拟合了一个“value model”
。作者基于这个思想,找到了entropy最低的一些位置作为关键位置,发现由此衍生出的rl效果很好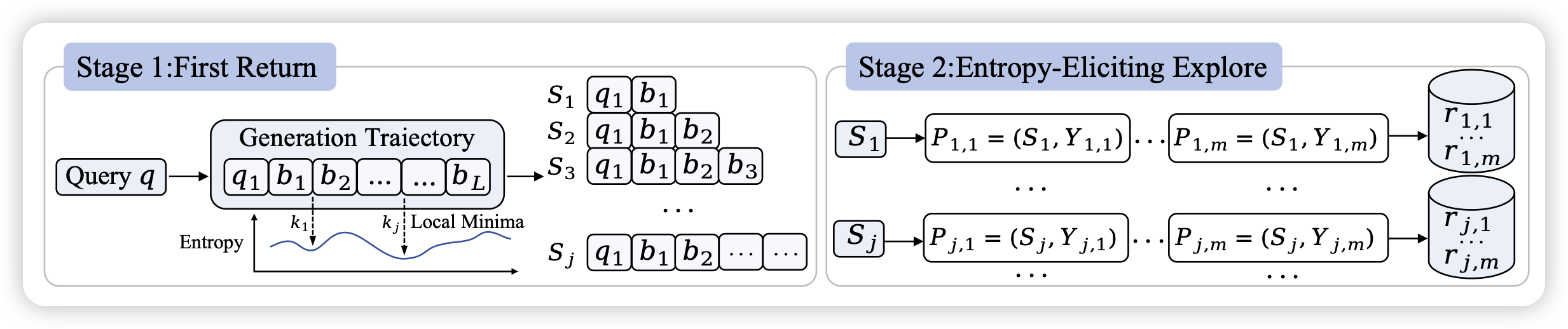
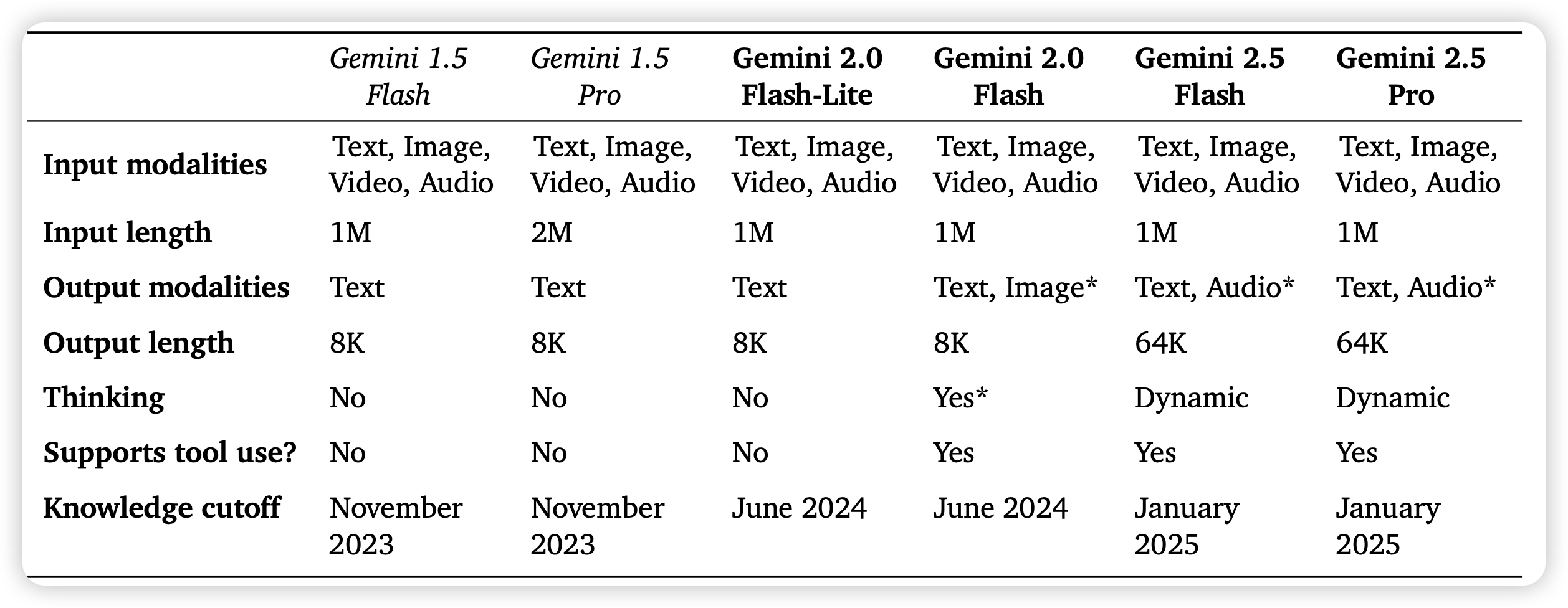
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities.
上来就是高手,这次主打的是快和便宜。不过报告里对于训练的技术和细节不多,当成宣传ppt看。