842篇,比上周还重量级……最近是怎么了
Point-RFT: Improving Multimodal Reasoning with Visually Grounded Reinforcement Finetuning
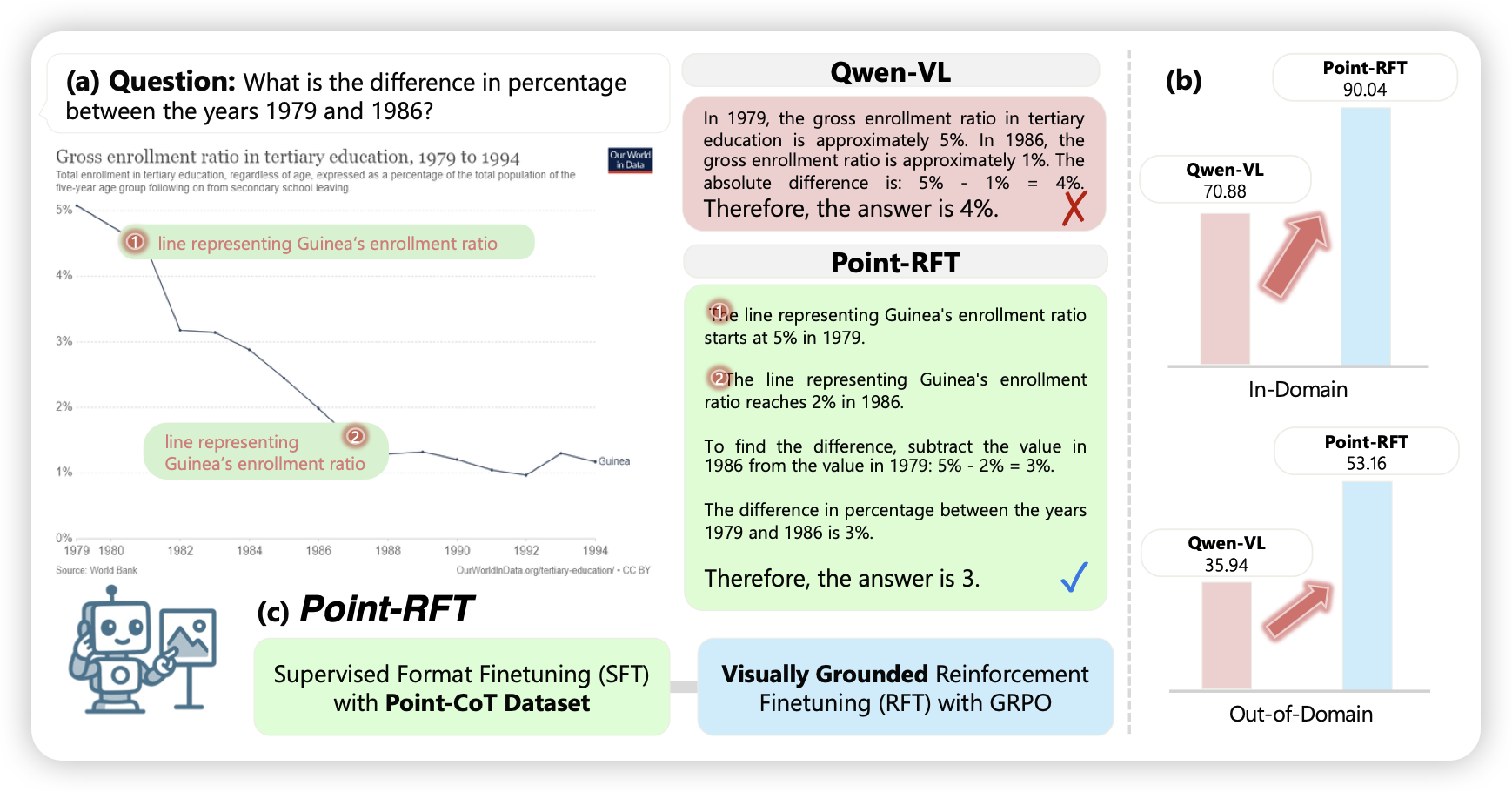
之前meta有一篇工作叫做pixmo,主要是找人录音描述图像,同时在图片里点击一些位置作为grounding,训出来的模型就可以在说话时掺杂一些坐标。这篇工作在rft的语境下增强这个能力,最终在一些infographic perception任务上做得很好。这个方法不新,但是作者整体开展挺流畅的
说话加坐标、放大图片、写代码处理图片输入,成为2025 VLM perception三幻神
ScreenExplorer: Training a Vision–Language Model for Diverse Exploration in Open GUI World
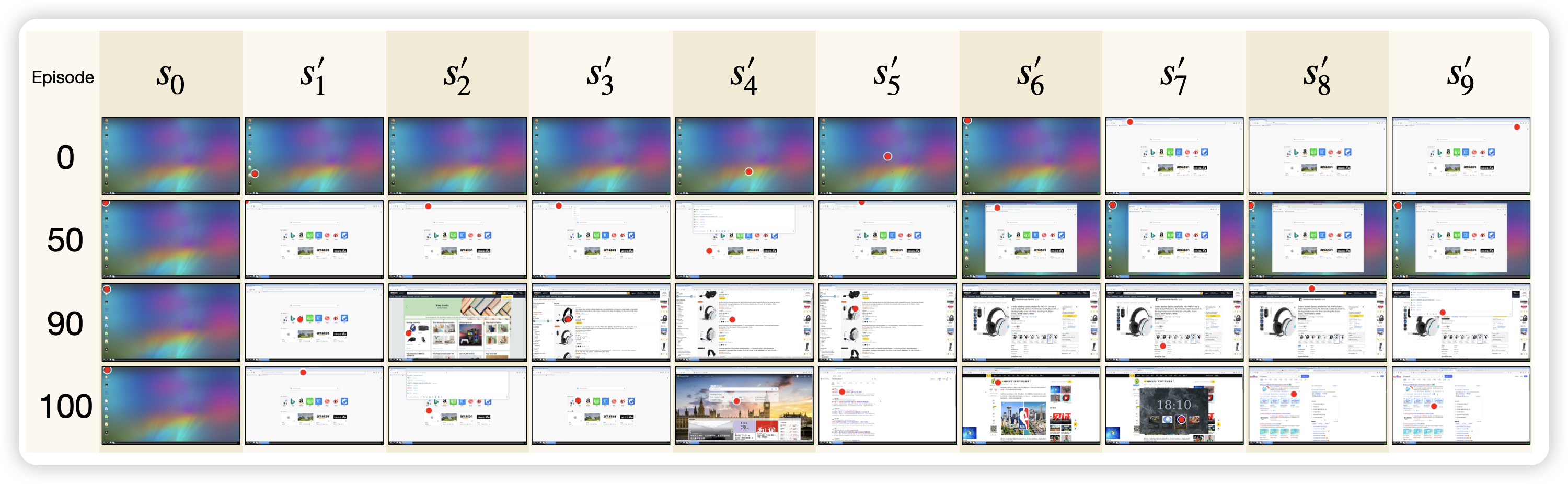
这篇工作里,作者做了一个setting叫做gui explore,意思是让模型从桌面开始,通过有限次键鼠操作,尽可能地多访问不同的页面。作者在这个setting上做了rl,发现可以正常地训练
感觉这个setting有点奇怪,是不是需要一些更end2end的任务,比如:如果explore更丰富了,那做自动地trace采集和出题会更高效?
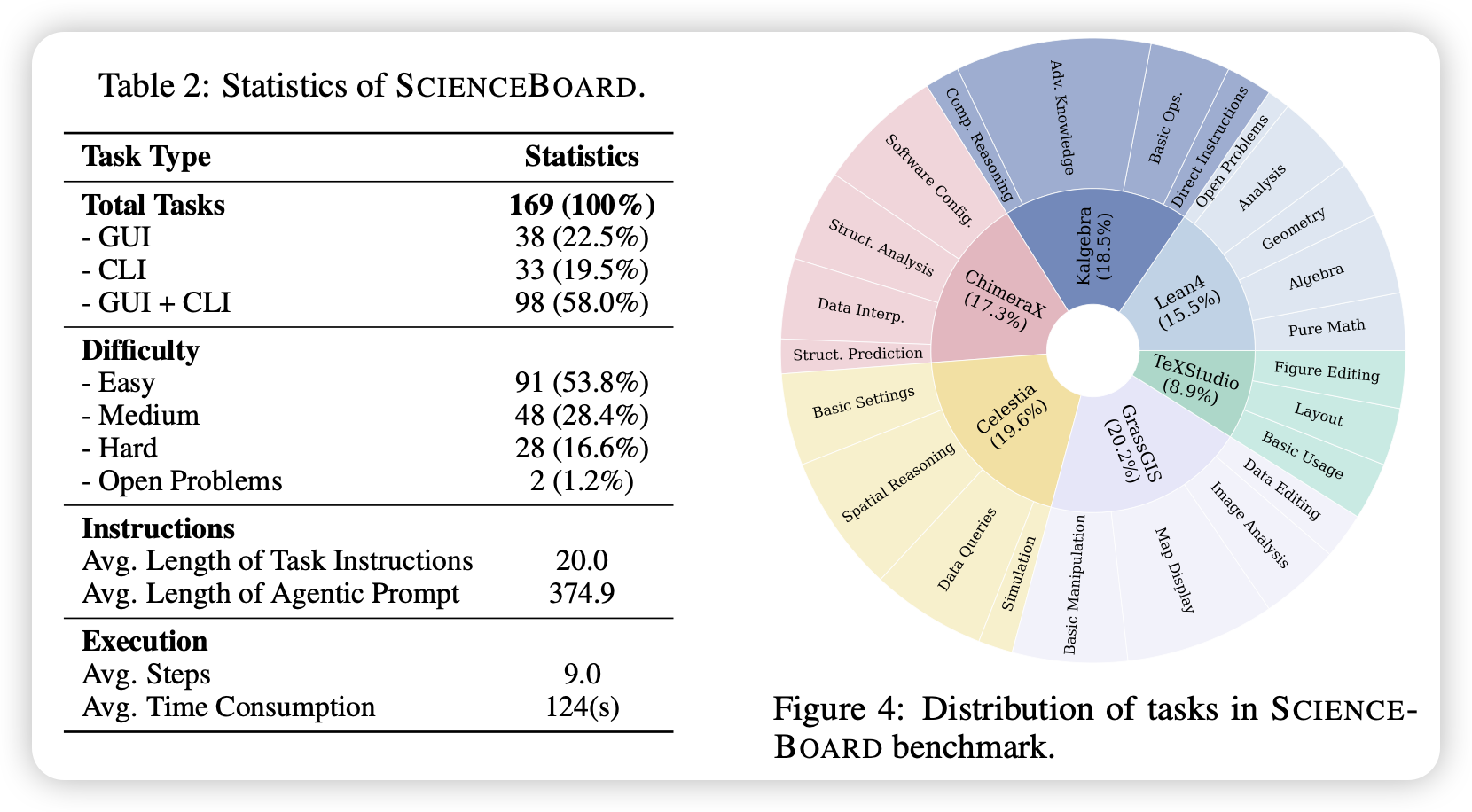
SCIENCEBOARD: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
推荐哥们的工作:作者仿造OSworld的设计方式,在几个专业科学软件上出题,测试了目前的MCP和GUI Agent在lean4等专业软件上的使用能力。