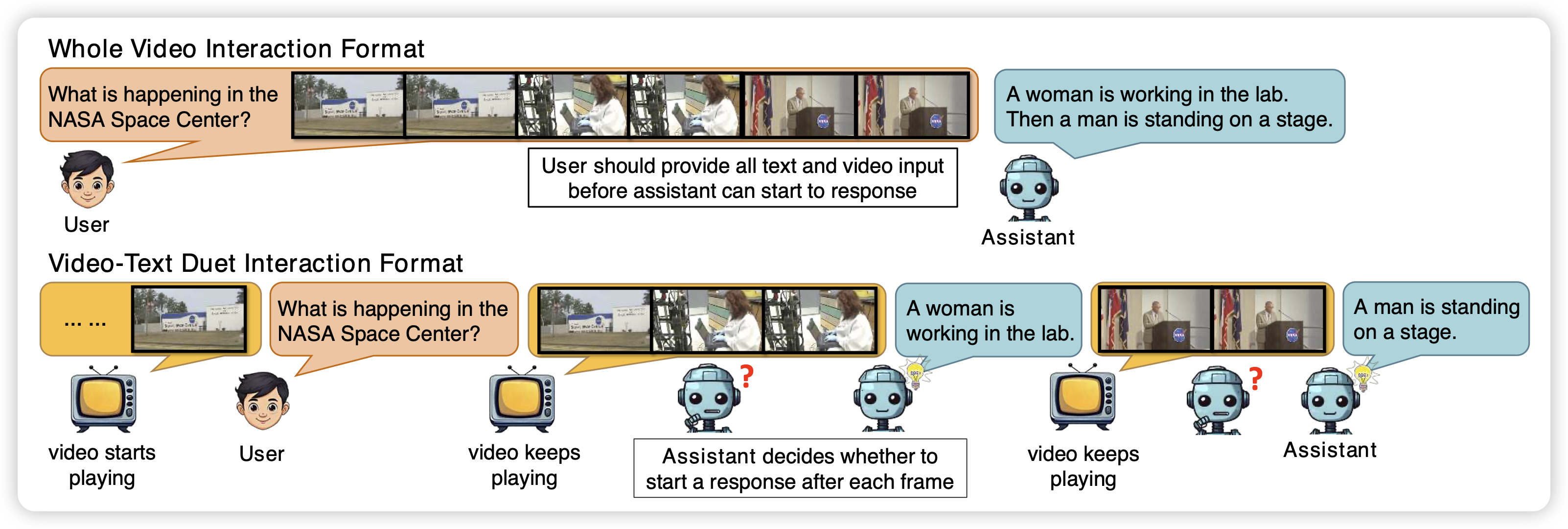
VideoLLM Knows When to Speak: Enhancing Time-Sensitive Video Comprehension with Video-Text Duet Interaction Format
一篇streaming video qa的工作。之前的所谓streaming video qa,都是在视频中间提问题,立即回答。这篇工作探索了一个更进一步的场景:用户提问,模型可能不会立即回答。
再加个打断,就是4o了
Enhancing Visual Reasoning with Autonomous Imagination in Multimodal Large Language Models
作者提到,能不能给VLM挂载一些图片处理action,让推理时可以变成多轮API 调用。作者试了一下,发现4o做得很好
下一篇论文: boostrapping visual reasoning with autonomous imagination distillation [doge]

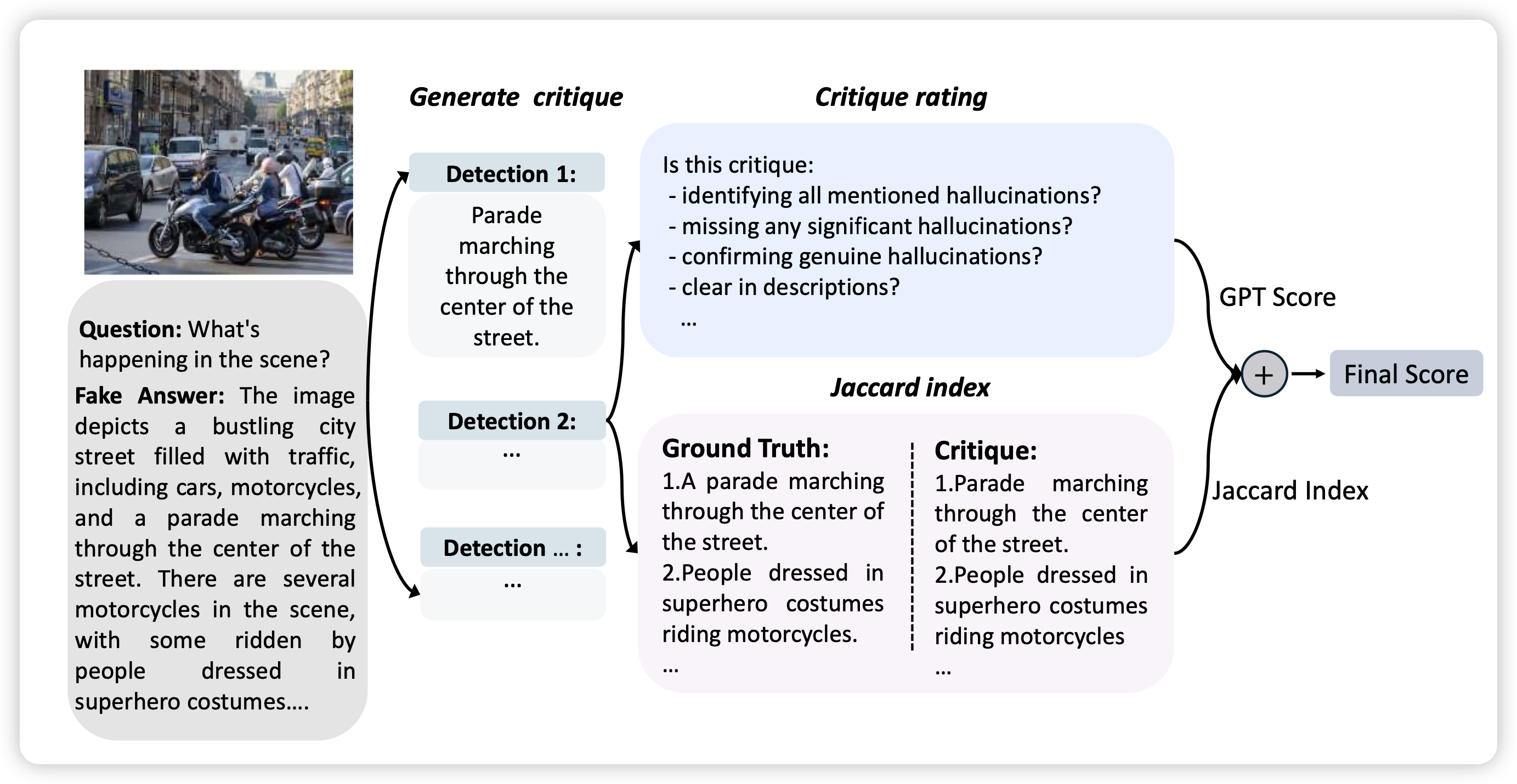
Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning
有趣的工作,作者想到一个办法:如果现在的VLM可以对VLM的错误给出一个自然语言的Critic,能不能设计一套actor-critic的训练框架把两个一起增强呢?
之前openAI有一篇工作叫做 LLM Critics Help Catch LLM Bugs...