今天来看一篇的新作,如何在不用模态对数据的情况下,炼多模态模型?甚至效果还行?

今天来看一篇的新作,如何在不用模态对数据的情况下,炼多模态模型?甚至效果还行?
今天来讲讲被称为transformer “后继有模”的retentive network网络:速度更快、占用更少、效果更好。

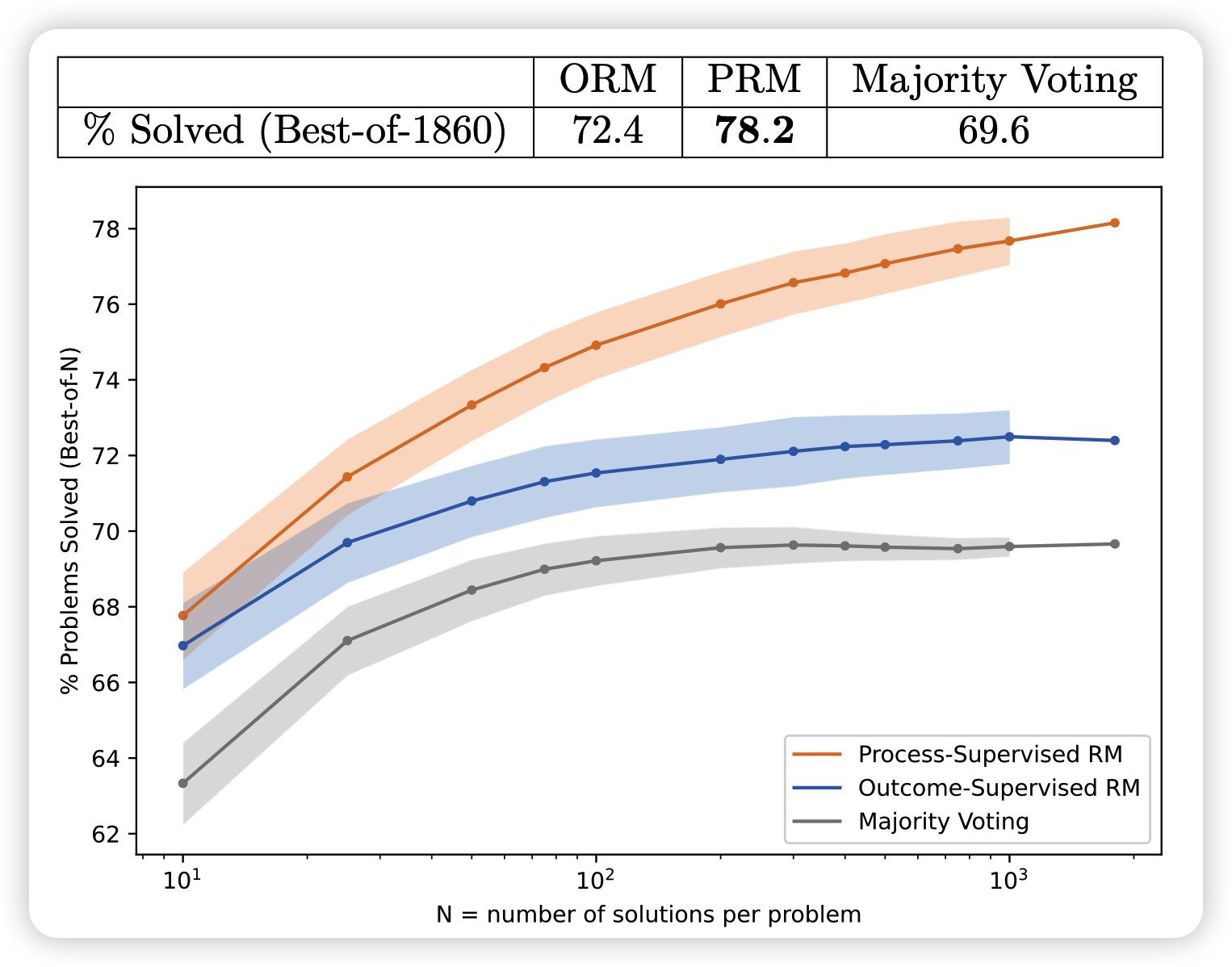
今天聊聊OpenAI 5月份发的一篇老论文:过程监督。这个说法是针对RLHF等技术的结果评价来讲的。他们使用过程监督的GPT4,在数学数据集上极大程度地战胜了结果监督的GPT4
如何仅用1000步训练(0.01%资源)就将一个在2k context长度上训练的预训练模型的上下文窗口拓展到32k
我其实不想讲这篇,因为我觉得苏剑林老师肯定会讲,并且讲的比我好,但是感觉这个方法还是很有研究价值的,因此分享给大家……


不知不觉就毕业了。
好长时间没写论文阅读笔记了,今天读一下LeCun讲了一年的”世界模型”:新的训练范式、训练快、参数少(0.6B)、效果好、方法简单、概念明确。
我在讲解时会说一些我的思路,因此我里面提到的一些优点、缺点有一些不是论文里说的是我自己的观点,完整故事逻辑大家可以去看原论文,论文写得很好。

论文介绍了一个非常简单的RLHF中PPO的替代品,昨天听了作者的报告,今天来仔细读读。我认为它的思路和calibration有一定的关系。

好久没写随笔了,今天一写突然发现好像博客快要更新一年了。这下子随笔的标题得把年份加上,和往年的时间加以区别了。笑死,让我想起了”千年虫”事件。这下我的博客要发生”一年虫“危机了。
千年虫:曾经的计算机使用2位十进制数计年,所以到了横跨世纪的时候就会报错
前两天看论文解释了emergent ability的出现原因猜想和复现,论文主要表达”涌现“没什么复杂的。我也聊聊我的看法。

之前看了阿西莫夫的小说《最后的问题》,里面讲到了宇宙里最令人绝望的定律”熵增定律“。今天讲讲人工智能领域最让人绝望的规律”emergent abilities“,在结合最优传输说说我对这个现象的理解,最后聊几个有趣的话题。参考:
Emergent Abilities of Large Language Models
Can LLMs Critique and Iterate on Their Own Outputs?
压缩下一个token通向超过人类的智能