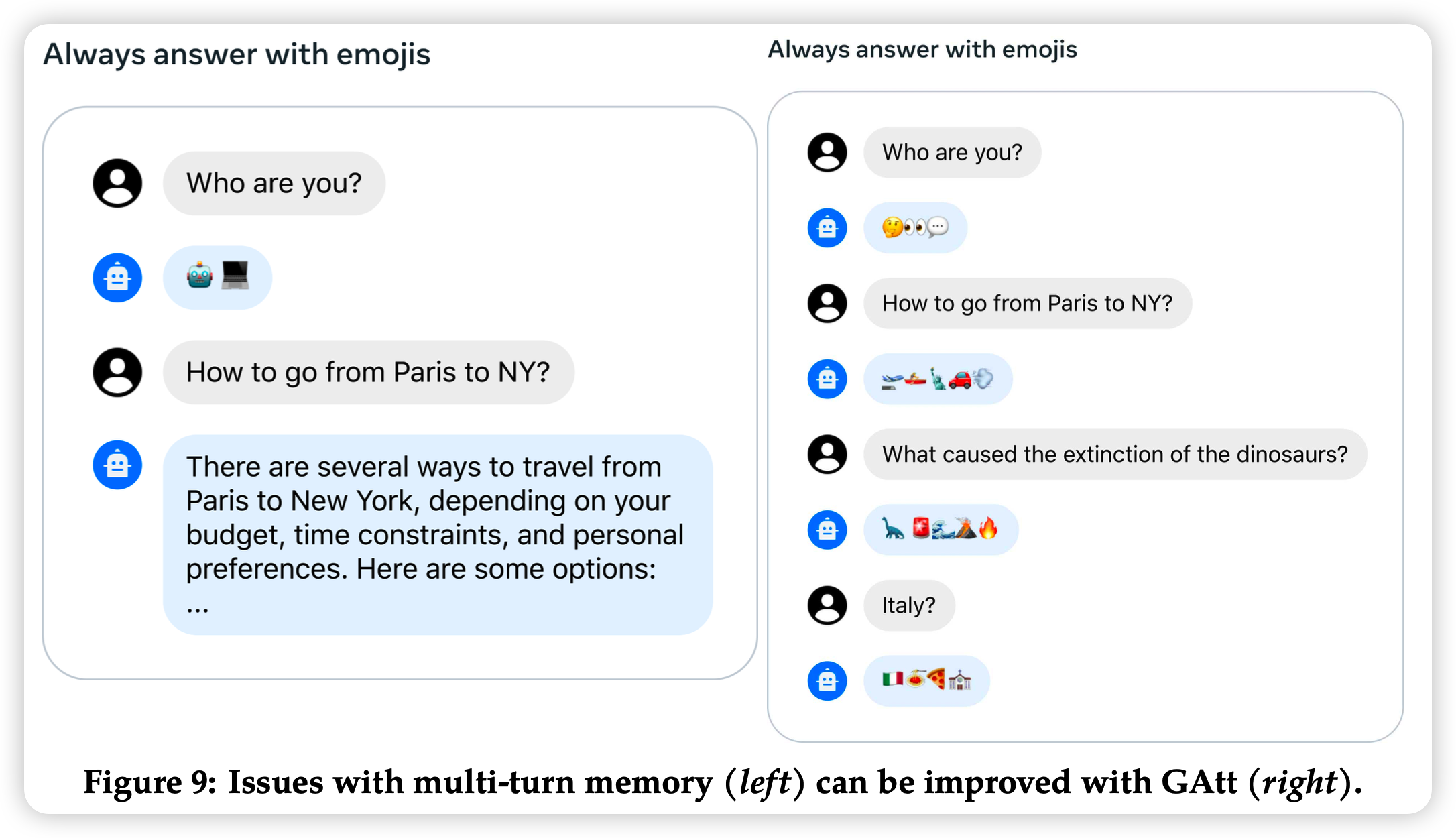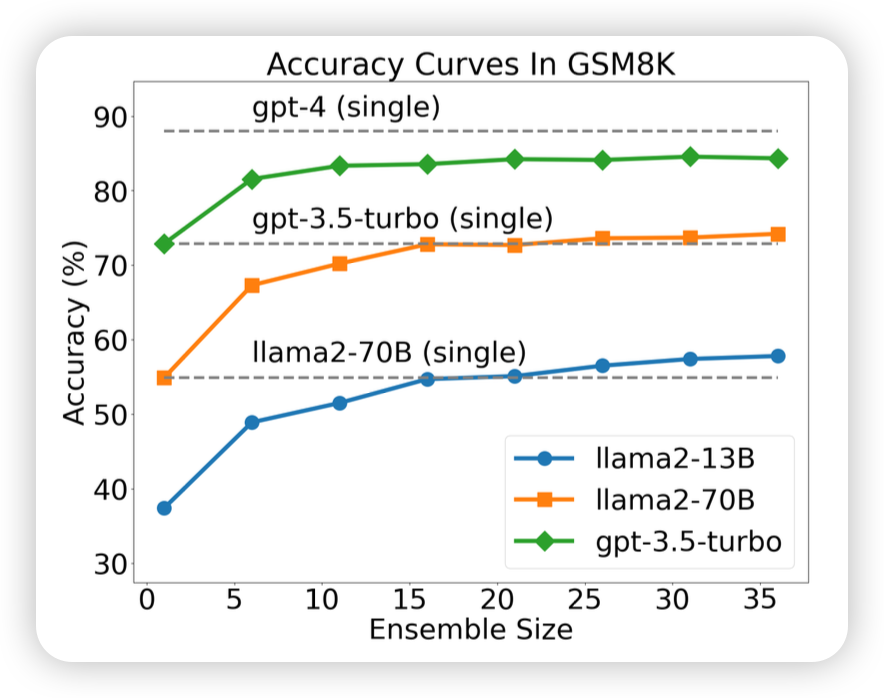
好久不更新了,看到之前大约都是15天更新一篇笔记,最近不知道咋回事竟然一个多月没更新,正好这两天刷到了”More Agents is All You Need”,就来讲讲“时间换效果”的鼻祖——self-consistency。如果让模型sample多次,然后做major-voting,效果会更好吗?
参考文献:
Self-Consistency Improves Chain of Thought Reasoning In Language Models
Escape Sky-High Cost: Early-Stopping Self-Consistency for Multi-Step Reasoning
Universal Self-Consistency for Large Language Model Generation
More Agents is All You Need
Unlock Predictable Scaling from Emergent Abilities