如何仅用1000步训练(0.01%资源)就将一个在2k context长度上训练的预训练模型的上下文窗口拓展到32k
我其实不想讲这篇,因为我觉得苏剑林老师肯定会讲,并且讲的比我好,但是感觉这个方法还是很有研究价值的,因此分享给大家……
作者团队是meta AI的田渊栋团队,他们之前做过挺多有意思的工作的

ROPE
这篇工作重点解决ROPE位置编码的预训练模型的问题,那么就先讲讲ROPE。具体可以看这篇
博采众长的旋转位置编码,写的比我写的好多了
简单来说,ROPE有如下特点:
- 不需要训练位置编码的参数
- 使用绝对位置编码的形式,就可以实现相对位置编码的效果。因此可以和FlashAttention等技术拼接来提高训练效率
- 理论上具有推广性,并不局限在整数”位置”

method
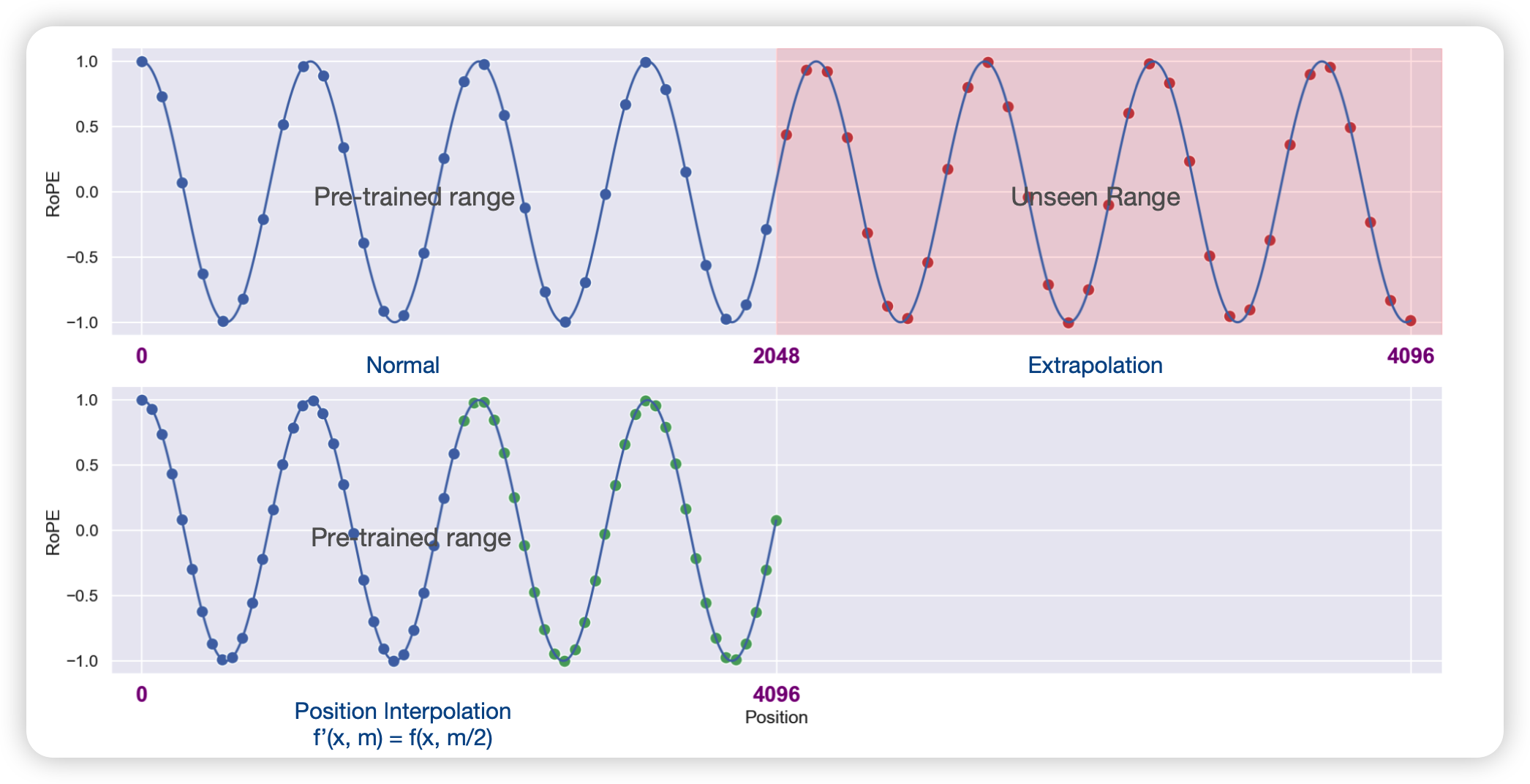
在本篇工作中,作者主要探索了怎么把一个ROPE训练的在2k,4k,8k的模型拓展到32k context window的场景。
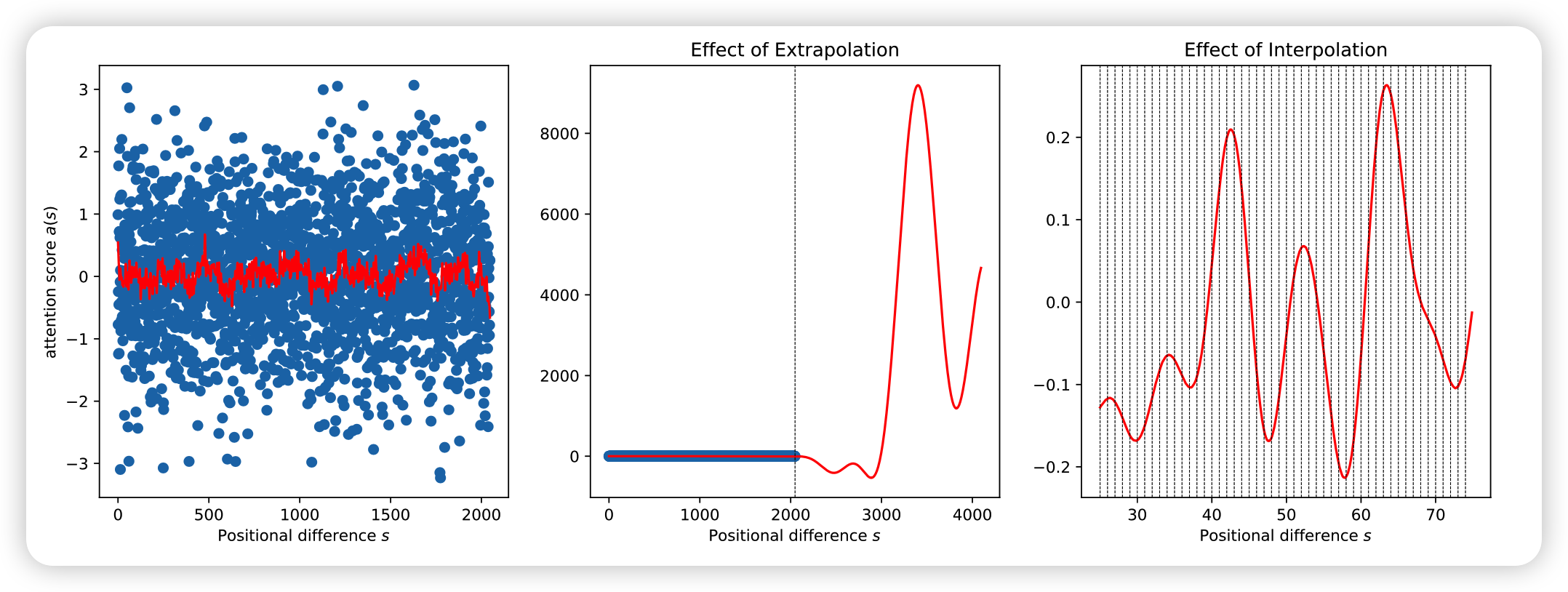
作者提到传统的ROPE算法在超出最大距离后,误差值就会爆炸,因此直接推广的效果一定是很差的,因此作者绕过了推广的限制:
外推不行,能不能内插?
答案是可以。
其中x是word embedding,m是位置。对于一个超过之前最大距离L的样本(距离为L’),通过内推将所有位置映射回L区间,每个位置都不再是整数。通过这种方式在长样本区间训练1000步,就能很好的应用到长样本上
作者用一堆数学证明这个的正确性,我没看懂,就不讲了。大家感兴趣可以自己看一看
接下来的实验部分都很简单,就是报告了一下效果。
我的思考
- 这篇论文的方法巨简单,但是效果很好、也很高效
- 我们可以思考一下:为什么这种方法可以work?我觉得主要是因为ROPE算法是一个推广的算法,本身就能拓展到非整数位置。理论上这类算法都可以这样拓展,比如BERT使用的那个基于cosine函数的绝对位置编码?
- 如果fine-tune时跑1000步就能这么好的话,那么在预训练阶段直接就加入这个内推过程是不是就更好呢?
- 如果从抽象的角度理解:看long text是一种看短text自然推广出的能力?